a
GraphQL服务器
我们在课程的前几部分中熟悉的REST,长期以来一直是实现服务器为浏览器提供接口的最普遍的方式,一般来说,也是网络上不同应用之间的整合。
近年来,由Facebook开发的GraphQL在网络应用和服务器之间的通信中变得流行起来。
GraphQL的理念与REST非常不同。REST是基于资源的。每个资源,例如一个用户,都有自己的地址来识别,例如/users/10。对资源进行的所有操作都是通过对其URL的HTTP请求完成的。该操作取决于所使用的HTTP方法。
REST的基于资源的特性在大多数情况下都很好用。然而,它有时也会有点尴尬。
让我们考虑下面的例子:我们的bloglist应用包含某种社会媒体功能,我们想显示一个由用户添加的所有博客的列表,这些用户在我们关注的任何博客上发表过评论。
如果服务器实现了REST API,我们可能需要从浏览器中进行多次HTTP请求,才能得到我们想要的所有数据。这些请求也会返回很多不必要的数据,而且浏览器上的代码可能会相当复杂。
如果这是一个经常使用的功能,可以有一个REST端点来实现。然而,如果有很多这样的场景,为所有这些场景实现REST端点将变得非常费力。
GraphQL服务器非常适用于这类情况。
GraphQL的主要原理是,浏览器上的代码形成一个描述所需数据的查询,并通过HTTP POST请求将其发送到API。与REST不同,所有GraphQL查询都被发送到同一个地址,其类型是POST。
上述场景中描述的数据可以通过(大致)以下查询来获取。
query FetchBlogsQuery {
user(username: "mluukkai") {
followedUsers {
blogs {
comments {
user {
blogs {
title
}
}
}
}
}
}
}"FetchBlogsQuery "的内容可以大致解释为:找到一个名为 "mluukkai "的用户,对于他的每个 "followedUsers",找到他们所有的 "博客",对于每个博客,所有的 "评论",对于每个写评论的 "用户",找到他们的 "博客",并返回其中的 "title"。
服务器的响应将是关于以下JSON对象。
{
"data": {
"followedUsers": [
{
"blogs": [
{
"comments": [
{
"user": {
"blogs": [
{
"title": "Goto considered harmful"
},
{
"title": "End to End Testing with Cypress is most enjoyable"
},
{
"title": "Navigating your transition to GraphQL"
},
{
"title": "From REST to GraphQL"
}
]
}
}
]
}
]
}
]
}
}应用逻辑保持简单,而浏览器上的代码通过一次查询就能得到它所需要的数据。
Schemas and queries
我们将通过实现第二和第三章节中的电话簿应用的GraphQL版本来了解GraphQL的基础知识。
在所有GraphQL应用的核心是一个模式,它描述了在客户端和服务器之间发送的数据。我们的电话簿的初始模式如下。
type Person {
name: String!
phone: String
street: String!
city: String!
id: ID!
}
type Query {
personCount: Int!
allPersons: [Person!]!
findPerson(name: String!): Person
}该模式描述了两种类型。第一个类型,人,决定了人有五个字段。其中四个字段是String类型,它是GraphQL的标量类型之一。
除了phone,所有的String字段都必须被赋予一个值。这在模式上以感叹号标示。字段id的类型是ID。ID字段是字符串,但GraphQL确保它们是唯一的。
第二种类型是 查询。实际上每个GraphQL模式都描述了一个查询,它告诉人们可以对API进行什么样的查询。
电话簿描述了三种不同的查询。personCount返回一个整数,allPersons返回一个Person对象的列表,findPerson给出一个字符串参数,它返回一个Person对象。
同样,感叹号被用来标记哪些返回值和参数是非空的。personCount肯定会返回一个整数。查询findPerson必须给一个字符串作为参数。该查询返回一个Person-object或null。allPersons返回一个Person对象的列表,并且这个列表不包含任何null值。
所以模式描述了客户端可以向服务器发送什么查询,查询可以有什么样的参数,以及查询返回什么样的数据。
最简单的查询,personCount,看起来如下。
query {
personCount
}假设我们的应用保存了三个人的信息,响应会是这样的。
{
"data": {
"personCount": 3
}
}获取所有的人的信息的查询,allPersons,有点复杂。因为该查询返回一个Person对象的列表,该查询必须说明 which fields of the objects the query returns:
query {
allPersons {
name
phone
}
}响应可能如下所示:
{
"data": {
"allPersons": [
{
"name": "Arto Hellas",
"phone": "040-123543"
},
{
"name": "Matti Luukkainen",
"phone": "040-432342"
},
{
"name": "Venla Ruuska",
"phone": null
}
]
}
}可以使查询返回模式中描述的任何字段。例如,下面的情况也是可以的。
query {
allPersons{
name
city
street
}
}最后一个例子显示了一个需要一个参数的查询,并返回一个人的详细信息。
query {
findPerson(name: "Arto Hellas") {
phone
city
street
id
}
}所以,首先,参数用圆括号描述,然后返回值对象的字段用大括号列出。
响应是这样的。
{
"data": {
"findPerson": {
"phone": "040-123543",
"city": "Espoo",
"street": "Tapiolankatu 5 A"
"id": "3d594650-3436-11e9-bc57-8b80ba54c431"
}
}
}返回值被标记为nullable,所以如果我们搜索一个未知的细节
query {
findPerson(name: "Joe Biden") {
phone
}
}返回值是null。
{
"data": {
"findPerson": null
}
}正如你所看到的,GraphQL查询和返回的JSON对象之间存在着直接的联系。我们可以认为,查询描述了它想要什么样的数据作为响应。
与REST查询的区别是明显的。在REST中,URL和请求的类型与返回数据的形式没有关系。
GraphQL查询只描述了在服务器和客户端之间移动的数据。在服务器上,数据可以以任何我们喜欢的方式组织和保存。
尽管它的名字,GraphQL实际上与数据库没有任何关系。它并不关心数据是如何被保存的。
GraphQL API使用的数据可以被保存到关系数据库、文档数据库或其他服务器,GraphQL服务器可以通过REST等方式访问。
Apollo Server
让我们用当今领先的库实现一个GraphQL服务器。Apollo Server。
用npm init创建一个新的npm项目,并安装所需的依赖项。
npm install apollo-server graphql同时在你的项目根目录下创建一个index.js文件。
初始代码如下。
const { ApolloServer, gql } = require('apollo-server')
let persons = [
{
name: "Arto Hellas",
phone: "040-123543",
street: "Tapiolankatu 5 A",
city: "Espoo",
id: "3d594650-3436-11e9-bc57-8b80ba54c431"
},
{
name: "Matti Luukkainen",
phone: "040-432342",
street: "Malminkaari 10 A",
city: "Helsinki",
id: '3d599470-3436-11e9-bc57-8b80ba54c431'
},
{
name: "Venla Ruuska",
street: "Nallemäentie 22 C",
city: "Helsinki",
id: '3d599471-3436-11e9-bc57-8b80ba54c431'
},
]
const typeDefs = gql`
type Person {
name: String!
phone: String
street: String!
city: String!
id: ID!
}
type Query {
personCount: Int!
allPersons: [Person!]!
findPerson(name: String!): Person
}
`
const resolvers = {
Query: {
personCount: () => persons.length,
allPersons: () => persons,
findPerson: (root, args) =>
persons.find(p => p.name === args.name)
}
}
const server = new ApolloServer({
typeDefs,
resolvers,
})
server.listen().then(({ url }) => {
console.log(`Server ready at ${url}`)
})代码的核心是一个ApolloServer,它被赋予两个参数。
const server = new ApolloServer({
typeDefs,
resolvers,
})第一个参数,typeDefs,包含GraphQL模式。
第二个参数是一个对象,它包含服务器的解析器。这些是代码,它定义了如何回应GraphQL查询。
解析器的代码如下。
const resolvers = {
Query: {
personCount: () => persons.length,
allPersons: () => persons,
findPerson: (root, args) =>
persons.find(p => p.name === args.name)
}
}正如你所看到的,解析器对应于模式中描述的查询。
type Query {
personCount: Int!
allPersons: [Person!]!
findPerson(name: String!): Person
}所以在Query下有一个字段,用于描述模式中的每个查询。
该查询
query {
personCount
}有解析器
() => persons.length所以对查询的响应是数组persons的长度。
取出所有人员的查询
query {
allPersons {
name
}
}有一个解析器,从persons数组中返回所有对象。
() => persons通过在终端运行node index.js来启动服务器。
Apollo Studio Explorer
当Apollo服务器在开发模式下运行时,页面http://localhost:4000有一个按钮查询你的服务器,将我们带到Apollo Studio Explorer。 这对开发者来说非常有用,可以用来对服务器进行查询。
让我们来试试吧。
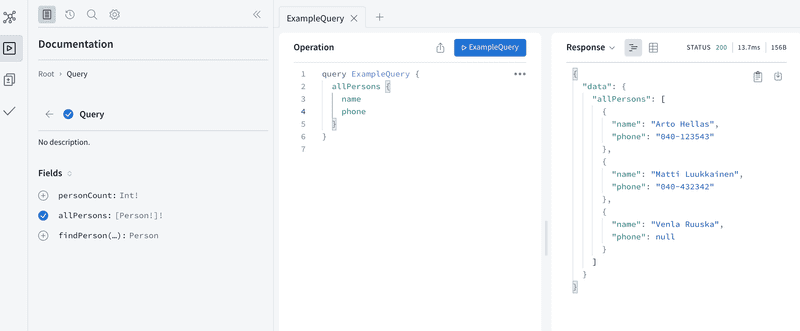
在左边的资源管理器显示了它根据模式自动生成的API文档。
Parameters of a resolver
获取一个人的查询
query {
findPerson(name: "Arto Hellas") {
phone
city
street
}
}有一个与之前不同的解析器,因为它被赋予了两个参数。
(root, args) => persons.find(p => p.name === args.name)第二个参数,args,包含查询的参数。
然后解析器从数组persons中返回名字与args.name的值相同的人。
解析器不需要第一个参数root。
事实上,所有的解析器函数都被赋予了四个参数。在JavaScript中,如果不需要这些参数,就不需要定义它们。我们将在本章节的后面使用解析器的第一个和第三个参数。
The default resolver
当我们做一个查询时,比如说
query {
findPerson(name: "Arto Hellas") {
phone
city
street
}
}服务器知道要准确地送回查询所需的字段。那是怎么发生的呢?
GraphQL服务器必须为模式中每种类型的每个字段定义解析器。
到目前为止,我们只为Query类型的字段定义了解析器,所以是为应用的每个查询定义的。
因为我们没有为Person类型的字段定义解析器,Apollo已经为它们定义了默认解析器。
它们的工作方式如下所示。
const resolvers = {
Query: {
personCount: () => persons.length,
allPersons: () => persons,
findPerson: (root, args) => persons.find(p => p.name === args.name)
},
Person: { name: (root) => root.name, phone: (root) => root.phone, street: (root) => root.street, city: (root) => root.city, id: (root) => root.id }}默认解析器返回对象的相应字段的值。对象本身可以通过解析器的第一个参数root访问。
如果默认解析器的功能足够了,你就不需要定义你自己的解析器。也可以只为一个类型的某些字段定义解析器,并让默认解析器处理其余的字段。
例如,我们可以定义所有人员的地址是 Manhattan New York by hard-coding the following to the resolvers of the street and city fields of the type Person:
Person: {
street: (root) => "Manhattan",
city: (root) => "New York"
}Object within an object
让我们稍微修改一下模式
type Address { street: String! city: String!}
type Person {
name: String!
phone: String
address: Address! id: ID!
}
type Query {
personCount: Int!
allPersons: [Person!]!
findPerson(name: String!): Person
}所以一个人现在有一个类型为Address的字段,其中包含街道和城市。
需要地址的查询变成了
query {
findPerson(name: "Arto Hellas") {
phone
address {
city
street
}
}
}响应现在是一个人的对象,它包含一个地址对象。
{
"data": {
"findPerson": {
"phone": "040-123543",
"address": {
"city": "Espoo",
"street": "Tapiolankatu 5 A"
}
}
}
}我们仍然以之前的方式在服务器中保存人员。
let persons = [
{
name: "Arto Hellas",
phone: "040-123543",
street: "Tapiolankatu 5 A",
city: "Espoo",
id: "3d594650-3436-11e9-bc57-8b80ba54c431"
},
// ...
]保存在服务器中的人物对象与模式中描述的GraphQL类型Person对象不完全相同。
与Person类型相反,Address类型没有一个id字段,因为它们没有被保存到服务器中自己的独立数据结构中。
因为保存在数组中的对象没有一个address字段,所以默认的解析器是不够的。
我们为Person类型的address字段添加一个解析器。
const resolvers = {
Query: {
personCount: () => persons.length,
allPersons: () => persons,
findPerson: (root, args) =>
persons.find(p => p.name === args.name)
},
Person: { address: (root) => { return { street: root.street, city: root.city } } }}所以每次返回 Person 对象时,字段 name、phone 和 id 会使用它们的默认解析器返回,但是字段 address 是通过使用自定义的解析器形成的。解析器函数的参数root是person-object,所以地址的街道和城市可以从其字段中获取。
该应用的当前代码可以在 Github找到,分支part8-1。
Mutations
让我们增加一个向电话簿添加新成员的功能。在GraphQL中,所有引起变化的操作都是通过mutations完成的。改变在模式中被描述为Mutation类型的键。
增加一个新人的改变的模式如下。
type Mutation {
addPerson(
name: String!
phone: String
street: String!
city: String!
): Person
}改变被赋予人的细节作为参数。参数phone是唯一一个可以归零的参数。改变也有一个返回值。返回值的类型是Person,意思是如果操作成功,将返回被添加的人的详细信息,如果不成功,则返回空。字段id的值不作为一个参数给出。生成一个id最好留给服务器。
改变也需要一个解析器。
const { v1: uuid } = require('uuid')
// ...
const resolvers = {
// ...
Mutation: {
addPerson: (root, args) => {
const person = { ...args, id: uuid() }
persons = persons.concat(person)
return person
}
}
}改变将作为参数args的对象添加到数组persons,并返回它添加到数组中的对象。
id字段使用uuid库被赋予一个唯一值。
一个新的人可以用以下的改变来添加
mutation {
addPerson(
name: "Pekka Mikkola"
phone: "045-2374321"
street: "Vilppulantie 25"
city: "Helsinki"
) {
name
phone
address{
city
street
}
id
}
}注意这个人被保存到persons数组中为
{
name: "Pekka Mikkola",
phone: "045-2374321",
street: "Vilppulantie 25",
city: "Helsinki",
id: "2b24e0b0-343c-11e9-8c2a-cb57c2bf804f"
}但是对这个改变的响应是
{
"data": {
"addPerson": {
"name": "Pekka Mikkola",
"phone": "045-2374321",
"address": {
"city": "Helsinki",
"street": "Vilppulantie 25"
},
"id": "2b24e0b0-343c-11e9-8c2a-cb57c2bf804f"
}
}
}所以Person类型的address字段的解析器将响应对象格式化为正确的形式。
Error handling
如果我们试图创建一个新的人,但参数与模式描述不一致,服务器会给出一个错误信息。
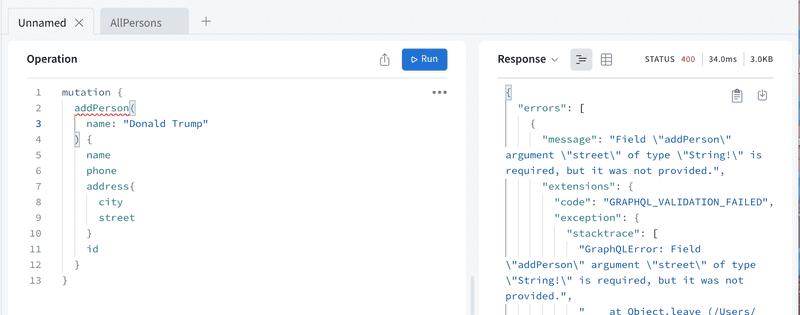
所以一些错误处理可以通过GraphQL验证自动完成。
然而,GraphQL不能自动处理所有的事情。例如,发送至改变的数据的更严格的规则必须手动添加。
这些规则的错误由Apollo服务器的错误处理机制来处理。
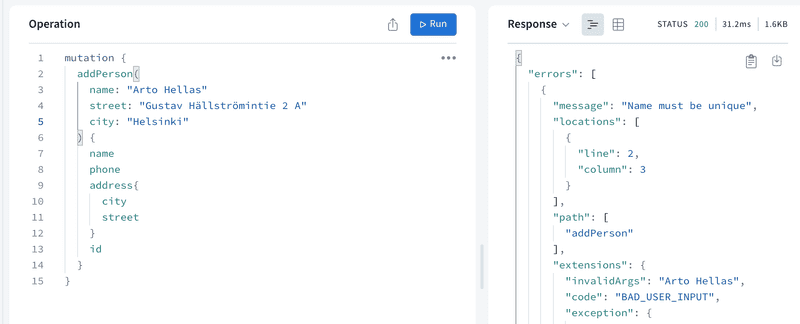
让我们阻止多次添加相同的名字到电话簿中。
const { ApolloServer, UserInputError, gql } = require('apollo-server')
// ...
const resolvers = {
// ..
Mutation: {
addPerson: (root, args) => {
if (persons.find(p => p.name === args.name)) { throw new UserInputError('Name must be unique', { invalidArgs: args.name, }) }
const person = { ...args, id: uuid() }
persons = persons.concat(person)
return person
}
}
}所以如果要添加的名字已经存在于电话簿中,抛出UserInputError错误。
该应用的当前代码可以在GitHub上找到,分支part8-2。
Enum
让我们增加一种可能性,用参数phone过滤返回所有人员的查询,这样它就只返回有电话号码的人员
query {
allPersons(phone: YES) {
name
phone
}
}或没有电话号码的人
query {
allPersons(phone: NO) {
name
}
}架构的变化是这样的。
enum YesNo { YES NO}
type Query {
personCount: Int!
allPersons(phone: YesNo): [Person!]! findPerson(name: String!): Person
}类型YesNo是一个GraphQL enum,或一个可列举的,有两个可能的值。YES或NO。在查询allPersons中,参数phone的类型是YesNo,但可以为空。
解析器的变化是这样的。
Query: {
personCount: () => persons.length,
allPersons: (root, args) => { if (!args.phone) { return persons } const byPhone = (person) => args.phone === 'YES' ? person.phone : !person.phone return persons.filter(byPhone) }, findPerson: (root, args) =>
persons.find(p => p.name === args.name)
},Changing a phone number
让我们添加一个用于改变一个人的电话号码的改变。这个改变的模式看起来如下。
type Mutation {
addPerson(
name: String!
phone: String
street: String!
city: String!
): Person
editNumber( name: String! phone: String! ): Person}并由一个解析器完成。
Mutation: {
// ...
editNumber: (root, args) => {
const person = persons.find(p => p.name === args.name)
if (!person) {
return null
}
const updatedPerson = { ...person, phone: args.phone }
persons = persons.map(p => p.name === args.name ? updatedPerson : p)
return updatedPerson
}
}该改变通过字段name找到要更新的人。
该应用的当前代码可以在Github上找到,分支part8-3。
More on queries
通过GraphQL,可以将多个Query类型的字段,或 "单独的查询 "结合到一个查询中。例如,下面的查询同时返回电话簿中的人员数量和他们的名字。
query {
personCount
allPersons {
name
}
}响应看起来如下。
{
"data": {
"personCount": 3,
"allPersons": [
{
"name": "Arto Hellas"
},
{
"name": "Matti Luukkainen"
},
{
"name": "Venla Ruuska"
}
]
}
}组合查询也可以多次使用同一查询。但是,你必须给这些查询取一个替代的名字,比如说。
query {
havePhone: allPersons(phone: YES){
name
}
phoneless: allPersons(phone: NO){
name
}
}响应如下所示:。
{
"data": {
"havePhone": [
{
"name": "Arto Hellas"
},
{
"name": "Matti Luukkainen"
}
],
"phoneless": [
{
"name": "Venla Ruuska"
}
]
}
}在某些情况下,给查询命名可能是有益的。特别是当查询或改变有参数时,就是这种情况。我们很快就会接触到参数。