c
Salvando dados no MongoDB
Antes de irmos ao assunto principal sobre persistência de dados em um banco de dados, vamos dar uma olhada em algumas maneiras diferentes de depurar aplicações Node.
Depurando aplicações Node
A depuração de aplicações Node é um tanto mais difícil do que depurar JavaScript em execução no navegador. A impressão de dados no console é um método testado e comprovado, e sempre vale a pena utilizá-lo. Algumas pessoas acham que métodos mais sofisticados devem ser usados em vez do console, mas eu discordo. Até os melhores desenvolvedores open-source do mundo usam esse método.
Visual Studio Code
O depurador do Visual Studio Code pode ser útil em algumas situações. Você pode iniciar a aplicação no modo de depuração assim:
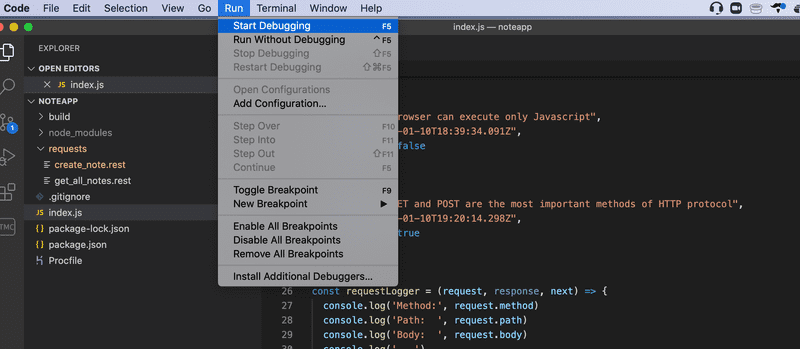
Observe que a aplicação não deve estar em execução em outro console, caso contrário, a porta já estará em uso.
Obs.: Uma versão mais recente do Visual Studio Code pode ter Run em vez de Debug. Além disso, talvez você precise configurar seu arquivo launch.json para iniciar a depuração. Isso pode ser feito selecionando Add Configuration... no menu, que está localizado ao lado do botão verde de play e acima do menu VARIABLES, selecionando Run "npm start" in a debug terminal. Para instruções de configuração mais detalhadas, leia a documentação sobre depuração do Visual Studio Code.
Abaixo você pode ver uma captura de tela onde a execução do código foi interrompida no meio do salvamento uma nova nota:
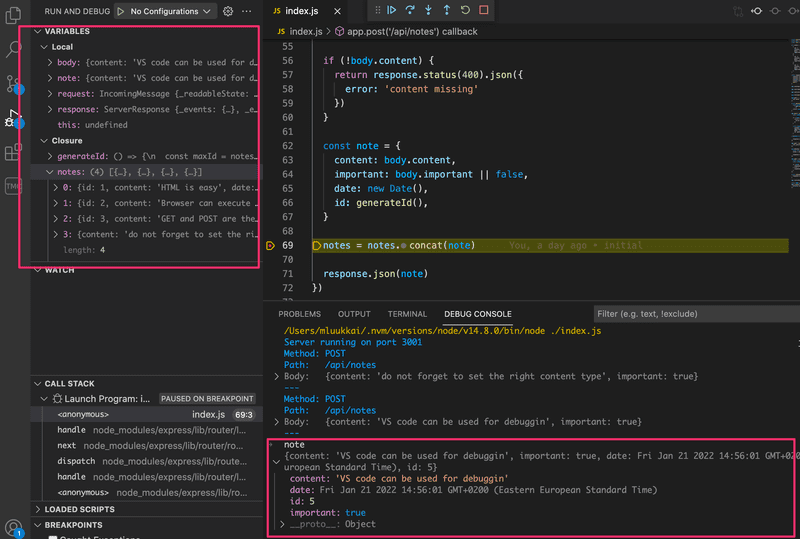
A execução parou no ponto de parada (breakpoint) na linha 69. É possível ver no console o valor da variável note. Na janela superior esquerda, é possível ver outras coisas relacionadas ao estado da aplicação.
As setas na parte superior podem ser usadas para controlar o fluxo do depurador.
Por alguma razão, eu não uso muito o depurador do Visual Studio Code.
As Ferramentas do Desenvolvedor do Chrome
Também é possível depurar o código com o Console do Desenvolvedor do Chrome, iniciando a aplicação com o comando:
node --inspect index.jsÉ possível acessar o depurador clicando no ícone verde — o logotipo do Node — que aparece no console de desenvolvedor do Chrome:

A visualização da depuração funciona da mesma maneira que fazíamos com as aplicações React. A guia Fontes (Sources) pode ser usada para definir pontos de parada onde a execução do código será pausada.
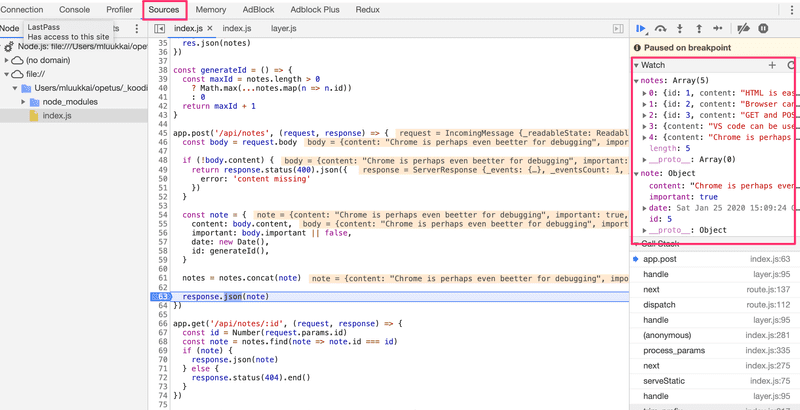
Todas as mensagens do console.log da aplicação aparecerão na guia Console do depurador. Também é possível inspecionar valores de variáveis e executar seu próprio código JavaScript.
Questione tudo!
Depurar aplicações Full Stack pode parecer complicado no início. Em breve, nossa aplicação também terá um banco de dados além do frontend e backend, e haverá muitas áreas potenciais para erros na aplicação.
Quando a aplicação "não funciona", primeiro precisamos descobrir onde o problema realmente está. É muito comum que o problema esteja em um lugar onde você menos esperava, e pode levar minutos, horas ou até mesmo dias antes de encontrar a fonte do problema.
O segredo é ser sistemático. Como o problema pode existir em qualquer lugar, você deve questionar tudo e eliminar todas as possibilidades uma por uma. Impressão de logs no console, Postman, depuradores e experiência ajudarão.
Quando bugs acontecem, a pior de todas as estratégias possíveis é continuar escrevendo mais código. Isso garantirá que seu código gere ainda mais bugs para frente, e depurá-los será ainda mais difícil. O princípio pare e corrija do Toyota Production Systems também é muito eficaz nessa situação.
MongoDB
Para armazenar indefinidamente nossas notas que estão sendo salvas, precisamos de um banco de dados. A maioria dos cursos ministrados na Universidade de Helsinque utiliza bancos de dados relacionais. Usaremos na maior parte deste curso o MongoDB, que é um tipo de banco de dados de documentos (document database).
A razão para usar o Mongo como banco de dados é devido a sua menor complexidade em comparação com um banco de dados relacional. A Parte 13 do curso mostra como construir backends em Node.js que usam um banco de dados relacional.
Bancos de dados de documentos diferem de bancos de dados relacionais em como eles organizam dados, bem como nas linguagens de consulta (query languages) que suportam. Bancos de dados de documentos são geralmente categorizados sob o termo genérico NoSQL (Not Only SQL [Não Somente SQL]).
É possível ler mais sobre bancos de dados de documentos e NoSQL no material do curso para a 7ª semana do curso de Introdução a Bancos de Dados. Infelizmente, o material está atualmente disponível apenas em finlandês.
Leia agora os capítulos sobre coleções (collections) e documentos (documents) do manual do MongoDB para ter uma ideia básica de como um banco de dados de documentos armazena dados.
Naturalmente, é possível instalar e executar o MongoDB em seu computador. Porém, a internet também está cheia de serviços de banco de dados Mongo que você pode usar. O provedor MongoDB preferido neste curso será o MongoDB Atlas.
Depois de criar e fazer login em sua conta, vamos começar selecionando o plano gratuito:
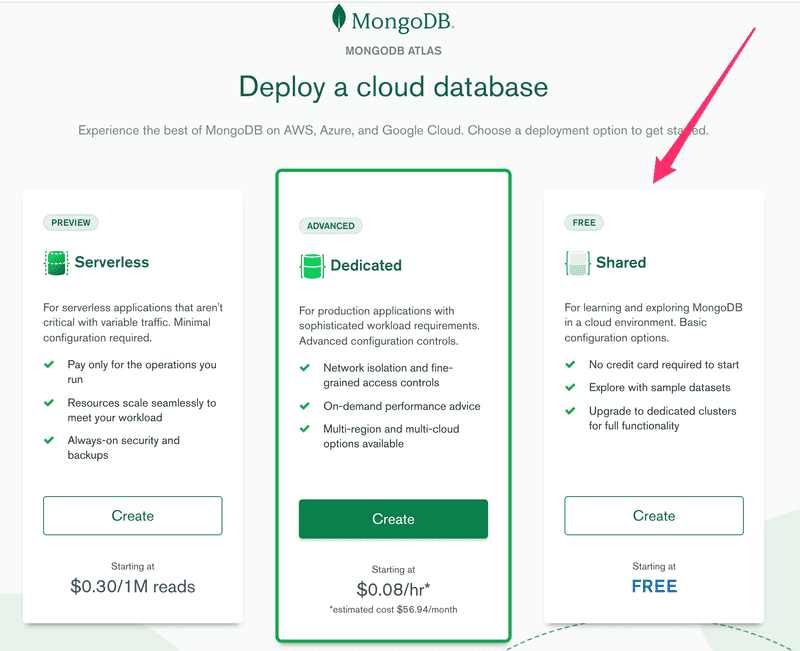
Escolha o provedor de nuvem e a localização e crie o cluster (grupo, aglomerado):
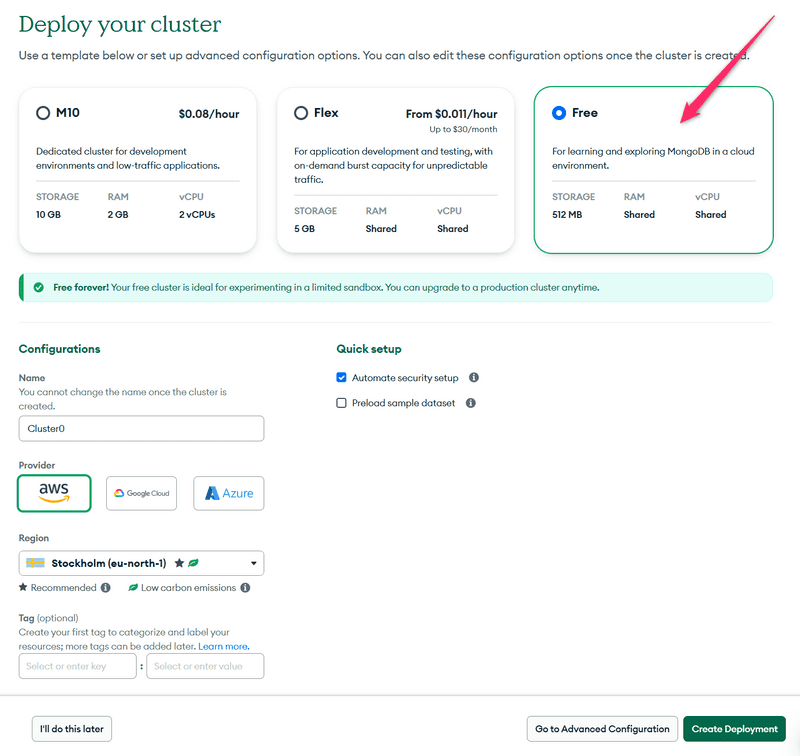
Vamos esperar o cluster ficar pronto para uso. Isso pode levar alguns minutos.
Obs.: não continue antes que o cluster esteja pronto.
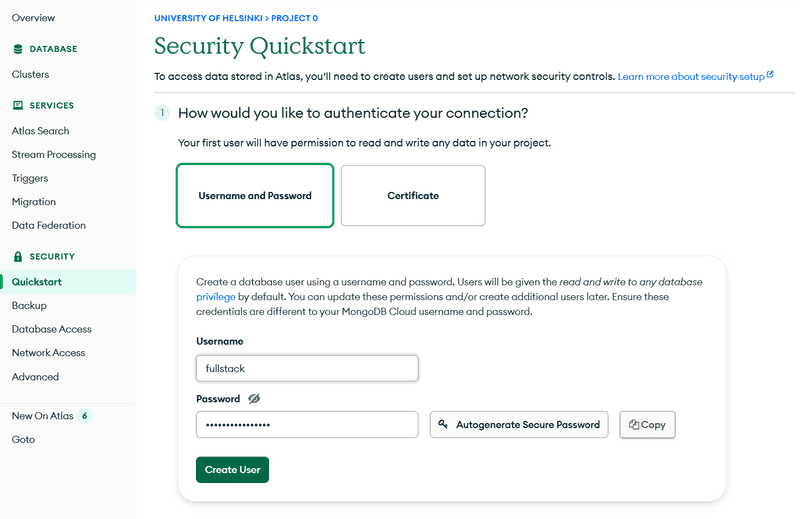
Vamos usar a guia security (segurança) para criar credenciais de usuário para o banco de dados. Observe que essas não são as mesmas credenciais que você usa para fazer login no MongoDB Atlas. Essas serão usadas para que sua aplicação se conecte ao banco de dados.
Em seguida, temos que definir os endereços IP que têm permissão de acesso ao banco de dados. Visando simplicidade, permitiremos o acesso de todos os endereços IP:
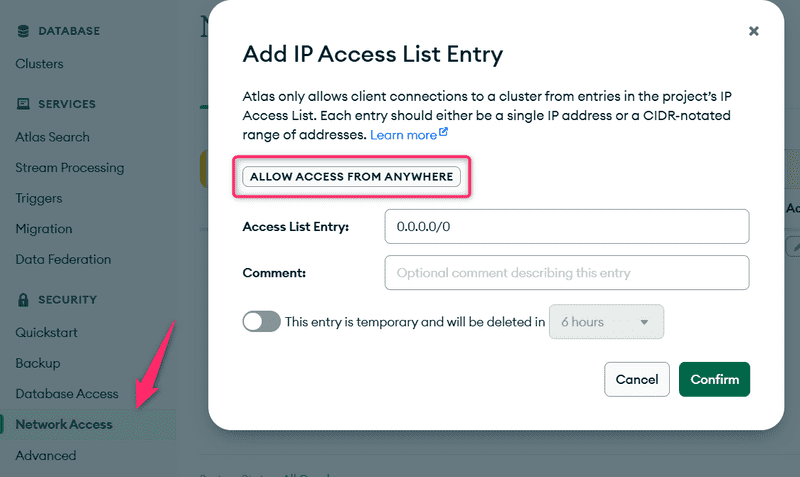
Observação: Se o menu modal for diferente para você, de acordo com a documentação do MongoDB, adicione 0.0.0.0 como o IP e allow access from anywhere (permitir acesso de qualquer lugar).
Por fim, estamos prontos para nos conectar ao nosso banco de dados. Comece clicando em connect (conectar).
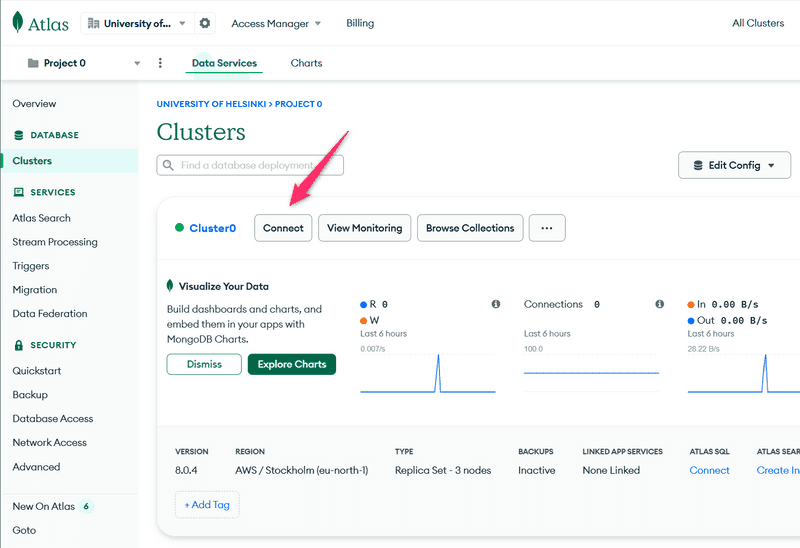
e escolha: Connect your application (Conecte sua aplicação):
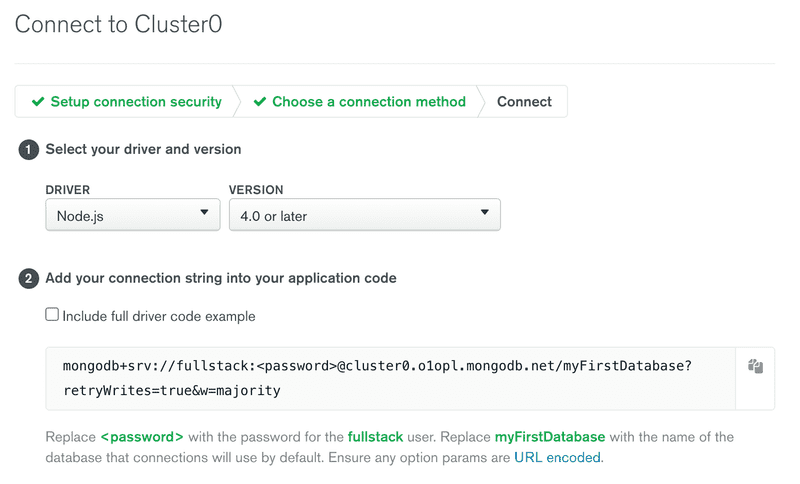
A imagem exibe o URI do MongoDB, que é o endereço do banco de dados que forneceremos à biblioteca-cliente do MongoDB que adicionaremos à nossa aplicação.
O endereço se parece com isso:
mongodb+srv://fullstack:thepasswordishere@cluster0.o1opl.mongodb.net/?retryWrites=true&w=majorityEstamos prontos para usar o banco de dados.
Poderíamos usar o banco de dados diretamente do nosso código JavaScript com a biblioteca oficial MongoDB Node.js Driver, mas ela é bastante complicada de usar. Em vez disso, usaremos a biblioteca Mongoose, que oferece uma API de alto nível.
Mongoose poderia ser descrito como um mapeador de documento-objeto (ODM [object document mapper]), que permite salvar diretamente objetos JavaScript como documentos Mongo.
Vamos instalar o Mongoose:
npm install mongooseAinda não vamos adicionar nenhum código relacionado ao Mongo em nosso backend. Em vez disso, vamos fazer uma aplicação prática criando um novo arquivo, mongo.js:
const mongoose = require('mongoose')
if (process.argv.length<3) {
console.log('give password as argument')
process.exit(1)
}
const password = process.argv[2]
const url =
`mongodb+srv://fullstack:${password}@cluster0.o1opl.mongodb.net/?retryWrites=true&w=majority`
mongoose.set('strictQuery',false)
mongoose.connect(url)
const noteSchema = new mongoose.Schema({
content: String,
important: Boolean,
})
const Note = mongoose.model('Note', noteSchema)
const note = new Note({
content: 'HTML is Easy',
important: true,
})
note.save().then(result => {
console.log('note saved!')
mongoose.connection.close()
})Obs.: Dependendo da região que você selecionou ao criar seu cluster, o URI do MongoDB pode ser diferente do exemplo fornecido acima. Você deve verificar e usar o URI correto que foi gerado pelo MongoDB Atlas.
O código também assume que será passada a senha das credenciais que criamos no MongoDB Atlas como um parâmetro de linha de comando. Podemos acessar o parâmetro da linha de comando assim:
const password = process.argv[2]Quando o código é executado com o comando node mongo.js password, o Mongo adicionará um novo documento ao banco de dados.
Obs.: Observe que a senha usada é a senha criada para o usuário do banco de dados, não a senha do MongoDB Atlas. Além disso, se criou uma senha com caracteres especiais, então você precisará codificar por cento sua senha (também conhecido como codificação URL ou URL encoding).
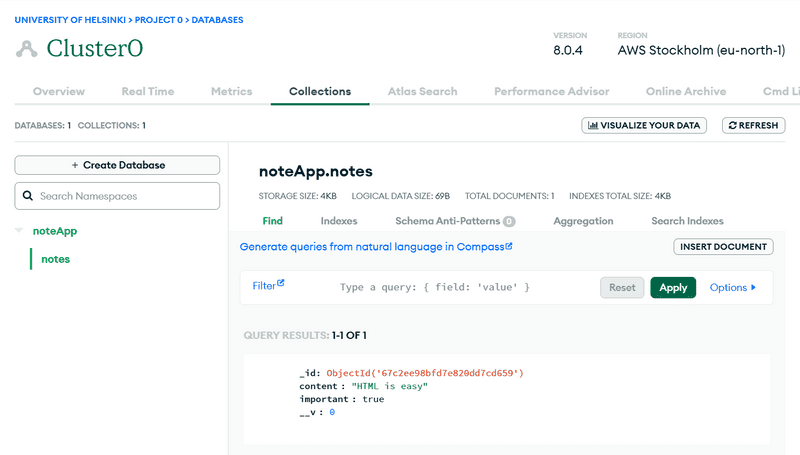
Podemos visualizar o estado atual do banco de dados do MongoDB Atlas a partir da guia Browse collections, na opção Databases.
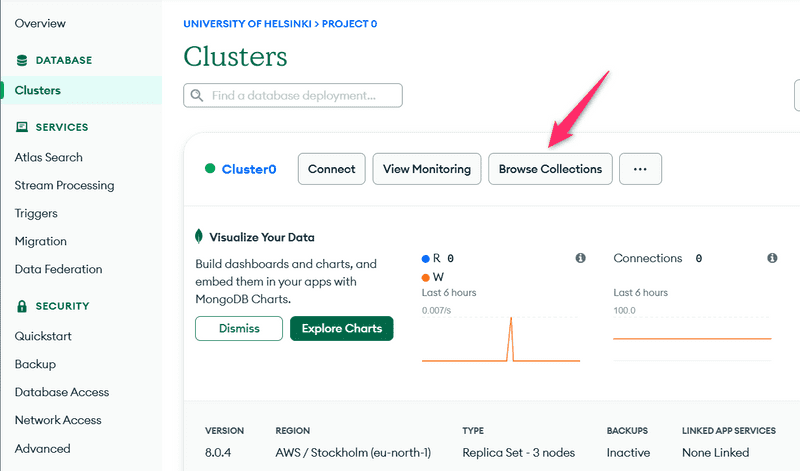
Como a imagem indica, o document (documento) correspondente à nota foi adicionado à coleção notes no banco de dados myFirstDatabase.
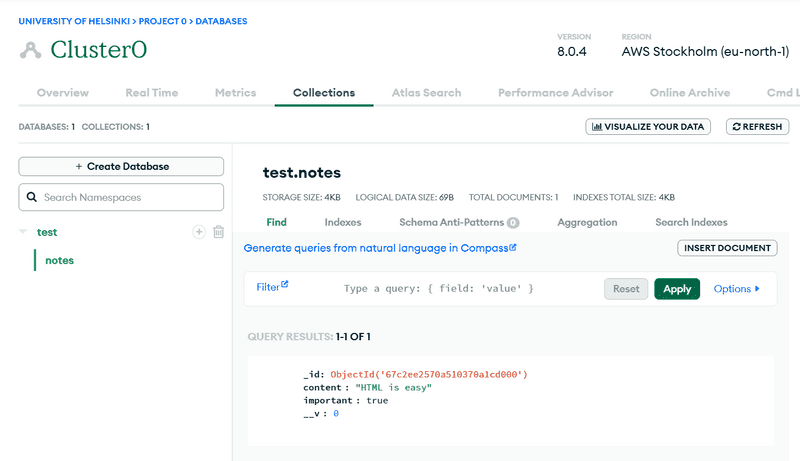
Vamos excluir o banco de dados padrão test e mudar o nome do banco de dados referenciado em nossa string de conexão para noteApp, modificando o URI:
const url =
`mongodb+srv://fullstack:${password}@cluster0.o1opl.mongodb.net/noteApp?retryWrites=true&w=majority`Vamos executar novamente nosso código:
Os dados agora estão armazenados no banco de dados correto. A visualização também oferece a funcionalidade create database (criar banco de dados), que pode ser usada para criar novos bancos de dados a partir da plataforma. Não é necessário criar um banco de dados dessa forma, pois o MongoDB Atlas cria automaticamente um novo banco de dados quando uma aplicação tenta se conectar a um banco de dados que ainda não existe.
Esquema (Schema)
Depois de estabelecer a conexão com o banco de dados, definimos o schema (esquema) para uma nota e o model (modelo) correspondente:
const noteSchema = new mongoose.Schema({
content: String,
important: Boolean,
})
const Note = mongoose.model('Note', noteSchema)Primeiro, definimos o schema de uma nota que é armazenada na variável noteSchema. O esquema informa ao Mongoose como os objetos de nota devem ser armazenados no banco de dados.
Na definição do modelo Note, o primeiro parâmetro "Note" é o nome singular do modelo. O nome da coleção será o plural notes em minúsculo, porque a convenção do Mongoose estabelece a nomeação automática de coleções com o seu plural (por exemplo, notes) quando o esquema se refere a elas no singular (por exemplo, Note).
Bancos de dados de documentos como o Mongo são schemaless (sem esquema), o que significa que o banco de dados em si não se importa com a estrutura dos dados armazenados no banco de dados. É possível armazenar documentos com campos completamente diferentes na mesma coleção.
A ideia por trás do Mongoose é que os dados armazenados no banco de dados recebam um esquema no nível da aplicação que define a forma dos documentos armazenados em qualquer coleção.
Criando e salvando objetos
Em seguida, a aplicação cria um novo objeto de nota com a ajuda do modelo Note:
const note = new Note({
content: 'HTML is Easy',
important: false,
})Modelos são chamados de funções construtoras (constructor functions) que criam novos objetos JavaScript com base nos parâmetros fornecidos. Como os objetos são criados com a função construtora do modelo, eles herdam todas as propriedades do modelo, que incluem métodos para salvar o objeto no banco de dados.
O salvamento do objeto no banco de dados ocorre com o método apropriadamente chamado save, que pode ser fornecido com um gerenciador de evento com o método then:
note.save().then(result => {
console.log('note saved!')
mongoose.connection.close()
})Quando o objeto é salvo no banco de dados, o gerenciador de evento fornecido para then é chamado. O gerenciador de evento fecha a conexão do banco de dados com o comando mongoose.connection.close(). Se a conexão não for fechada, o programa nunca terminará sua execução.
O resultado da operação de salvamento está no parâmetro result do gerenciador de evento. O resultado não é lá muito interessante quando estamos armazenando um objeto no banco de dados. Você pode imprimir o objeto no console se quiser examiná-lo mais de perto enquanto implementa sua aplicação ou durante a depuração.
Vamos também salvar algumas notas adicionais modificando os dados no código e executando o programa novamente.
Obs.: Infelizmente, a documentação do Mongoose não é muito consistente: usam callbacks em alguns de seus exemplos; em outras partes, outros estilos. Portanto, não é recomendado copiar e colar o código diretamente de lá. Misturar promessas com callbacks antigos no mesmo código não é recomendado.
Recuperando objetos do banco de dados
Vamos comentar o código que gera novas notas e adicionemos o seguinte:
Note.find({}).then(result => {
result.forEach(note => {
console.log(note)
})
mongoose.connection.close()
})Quando o código é executado, o programa imprime todas as notas armazenadas no banco de dados:
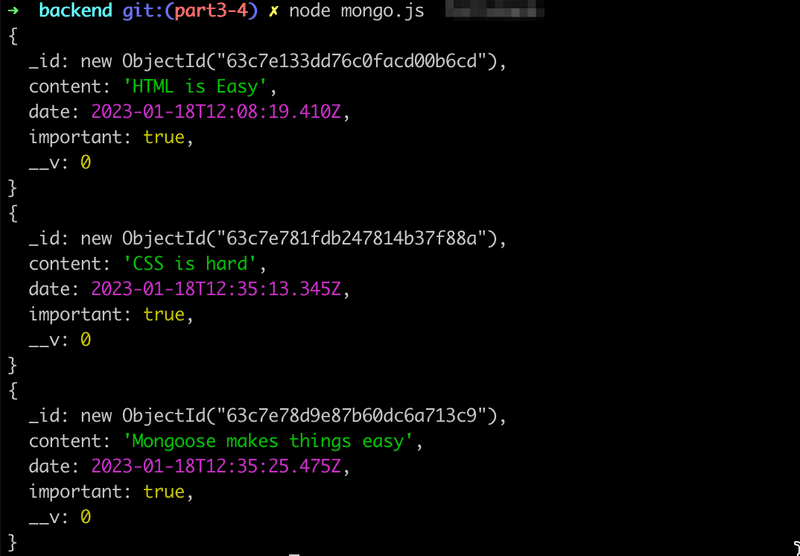
Os objetos são recuperados do banco de dados com o método find do modelo Note. O parâmetro do método é um objeto que expressa condições de pesquisa. Como o parâmetro é um objeto vazio{}, obtemos todas as notas armazenadas na coleção notes.
As condições de pesquisa aderem à sintaxe de consulta do Mongo.
Podemos restringir nossa pesquisa incluindo apenas notas importantes:
Note.find({ important: true }).then(result => {
// ...
})Conectando o backend a um banco de dados
Agora temos conhecimento suficiente para começar a usar o Mongo em nossa aplicação.
Vamos rapidamente copiar e colar as definições do Mongoose no arquivo index.js:
const mongoose = require('mongoose')
// NÃO SALVE SUA SENHA NO GITHUB!!
const url =
`mongodb+srv://fullstack:${password}@cluster0.o1opl.mongodb.net/?retryWrites=true&w=majority`
mongoose.set('strictQuery',false)
mongoose.connect(url)
const noteSchema = new mongoose.Schema({
content: String,
important: Boolean,
})
const Note = mongoose.model('Note', noteSchema)Vamos mudar o gerenciador para buscar todas as notas da seguinte forma:
app.get('/api/notes', (request, response) => {
Note.find({}).then(notes => {
response.json(notes)
})
})Podemos verificar no navegador que o backend funciona na medida em que exibe todos os documentos:
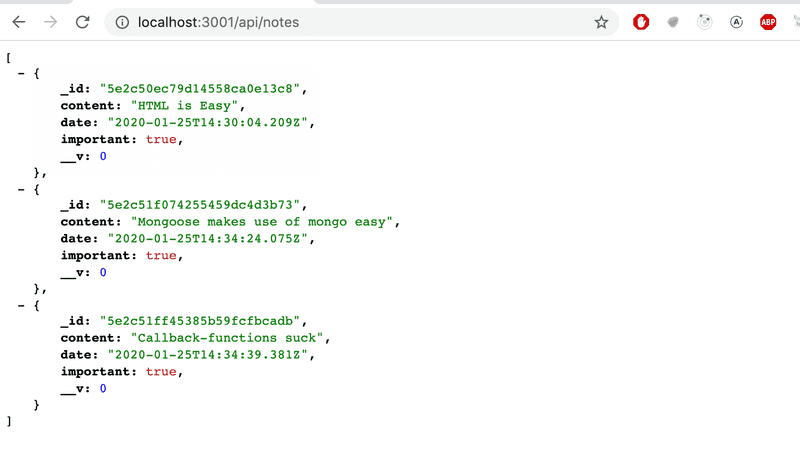
A aplicação funciona quase perfeitamente. O frontend assume que cada objeto tem um id único no campo id. Também não queremos retornar o campo de versionamento do Mongo __v para o frontend.
Uma maneira de formatar os objetos retornados pelo Mongoose é modificar o método toJSON do esquema, que é usado em todas as instâncias dos modelos produzidos com esse esquema.
Para modificar o método, precisamos alterar as opções configuráveis do esquema. As opções podem ser alteradas usando o método set do esquema. Entre aqui para obter mais informações sobre este método: https://mongoosejs.com/docs/guide.html#options. Veja https://mongoosejs.com/docs/guide.html#toJSON e https://mongoosejs.com/docs/api.html#document_Document-toObject para obter mais informações sobre a opção toJSON.
Entre no link https://mongoosejs.com/docs/api.html#transform para obter mais informações sobre a função de transformação (transform function).
noteSchema.set('toJSON', {
transform: (document, returnedObject) => {
returnedObject.id = returnedObject._id.toString()
delete returnedObject._id
delete returnedObject.__v
}
})Embora a propriedade _id dos objetos Mongoose pareça uma string, na verdade é um objeto. O método toJSON que definimos transforma-o em uma string como garantia. Se não fizéssemos essa mudança, isso nos causaria mais problemas no futuro quando começássemos a escrever testes.
Nenhuma mudança é necessária no gerenciador:
app.get('/api/notes', (request, response) => {
Note.find({}).then(notes => {
response.json(notes)
})
})O código usa automaticamente o já definido toJSON quando formata as notas para serem enviadas como resposta.
A configuração do banco de dados em seu próprio módulo
Antes de refatorarmos o restante do backend para usar o banco de dados, vamos extrair o código específico do Mongoose em seu próprio módulo.
Vamos criar um novo diretório para o módulo chamado models, onde adicionaremos um arquivo chamado note.js:
const mongoose = require('mongoose')
mongoose.set('strictQuery', false)
const url = process.env.MONGODB_URI
console.log('connecting to', url)
mongoose.connect(url)
.then(result => { console.log('connected to MongoDB') }) .catch((error) => { console.log('error connecting to MongoDB:', error.message) })
const noteSchema = new mongoose.Schema({
content: String,
important: Boolean,
})
noteSchema.set('toJSON', {
transform: (document, returnedObject) => {
returnedObject.id = returnedObject._id.toString()
delete returnedObject._id
delete returnedObject.__v
}
})
module.exports = mongoose.model('Note', noteSchema)A definição de módulos do Node difere um pouco da maneira de definir módulos ES6 da Parte 2.
A interface pública do módulo é estabelecida ao definir um valor para a variável module.exports. Vamos definir o valor como o modelo Note. As outras coisas definidas dentro do módulo, como as variáveis mongoose e url, não serão acessíveis ou visíveis para os usuários do módulo.
A importação do módulo acontece adicionando a seguinte linha no arquivo index.js:
const Note = require('./models/note')Dessa forma, a variável Note será atribuída ao mesmo objeto que o módulo define.
A forma como a conexão é feita mudou um pouco:
const url = process.env.MONGODB_URI
console.log('connecting to', url)
mongoose.connect(url)
.then(result => {
console.log('connected to MongoDB')
})
.catch((error) => {
console.log('error connecting to MongoDB:', error.message)
})Não é uma boa ideia colocar o endereço do banco de dados no código; então, em vez disso, o endereço do banco de dados é passado para a aplicação através da variável de ambiente MONGODB_URI.
Agora, o método para estabelecer a conexão recebe funções para lidar com uma tentativa de conexão bem-sucedida e mal-sucedida. Ambas as funções registram apenas uma mensagem no console sobre o status de sucesso:

Existem muitas maneiras de definir o valor de uma variável de ambiente. Uma maneira seria defini-la quando a aplicação é iniciada:
MONGODB_URI=address_here npm run devUma maneira mais sofisticada é usar a biblioteca dotenv. É possível instalá-la com o comando:
npm install dotenvPara usar a biblioteca, criamos um arquivo .env na raiz do projeto. As variáveis de ambiente são definidas dentro do arquivo, coisa que se parece assim:
MONGODB_URI=mongodb+srv://fullstack:thepasswordishere@cluster0.o1opl.mongodb.net/noteApp?retryWrites=true&w=majority
PORT=3001Também adicionamos a porta indicada do servidor na variável de ambiente PORT.
O arquivo .env deve ser ignorado (adicionado ao arquivo .gitignore) imediatamente, pois não queremos publicar informações confidenciais na internet!

As variáveis de ambiente definidas no arquivo .env podem ser utilizadas com a expressão require('dotenv').config(), onde é possível se referir a elas em seu código da mesma maneira que você se refere a variáveis de ambiente normais, com a já familiar sintaxe process.env.MONGODB_URI.
Vamos mudar o arquivo index.js da seguinte maneira:
require('dotenv').config()const express = require('express')
const app = express()
const Note = require('./models/note')
// ..
const PORT = process.env.PORTapp.listen(PORT, () => {
console.log(`Server running on port (Servidor em execução na porta) ${PORT}`)
})É importante que o dotenv seja importado antes do modelo note. Isso garante que as variáveis de ambiente do arquivo .env estejam disponíveis globalmente antes que o código dos outros módulos seja importado.
Nota importante para usuários do Fly.io
Como o GitHub não é usado com Fly.io, o arquivo .env também é enviado para os servidores Fly.io quando a aplicação é implantada. Por causa disso, as variáveis de ambiente definidas no arquivo também estarão disponíveis lá.
No entanto, uma opção melhor é impedir que .env seja copiado ao Fly.io criando, na raiz do projeto, o arquivo .dockerignore com o seguinte conteúdo:
.envDefina o valor da variável de ambiente na linha de comando desta forma:
fly secrets set MONGODB_URI='mongodb+srv://fullstack:thepasswordishere@cluster0.o1opl.mongodb.net/noteApp?retryWrites=true&w=majority'Já que a variável PORT também é definida em nosso .env, é essencial ignorar o arquivo no Fly.io, caso contrário, a aplicação iniciará na porta errada.
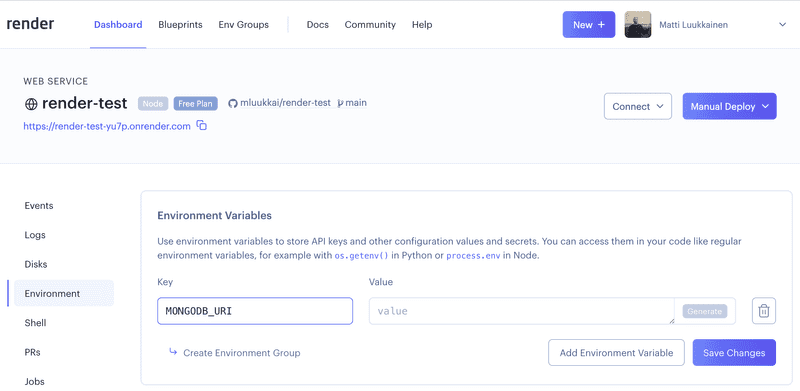
Ao usar o Render, a url do banco de dados é fornecida definindo a variável de ambiente adequada no painel:
Usando o banco de dados em gerenciadores de evento de rotas
Agora, vamos mudar o resto da funcionalidade do backend para usar o banco de dados.
Cria-se uma nova nota desta forma:
app.post('/api/notes', (request, response) => {
const body = request.body
if (body.content === undefined) {
return response.status(400).json({ error: 'content missing' })
}
const note = new Note({
content: body.content,
important: body.important || false,
})
note.save().then(savedNote => {
response.json(savedNote)
})
})Os objetos de note são criados com a função construtora Note. A resposta é enviada dentro da função callback para a operação save. Isso garante que a resposta seja enviada somente se a operação tiver sucesso. Discutiremos sobre gerenciamento de erros um pouco mais tarde.
O parâmetro savedNote na função callback é a nota salva e recém-criada. Os dados enviados de volta na resposta são a versão formatada criada automaticamente com o método toJSON:
response.json(savedNote)Busca-se uma nota individual utilizando o método findById (grosso modo, "acharPorId") do Mongoose, onde nosso código altera-se da seguinte forma:
app.get('/api/notes/:id', (request, response) => {
Note.findById(request.params.id).then(note => {
response.json(note)
})
})Verificando a integração entre frontend e backend
Ao se expandir o backend, sempre é uma boa ideia testá-lo primeiro com o navegador, com o Postman ou com o cliente REST do VS Code. Em seguida, vamos tentar criar uma nova nota depois colocar o banco de dados em uso:
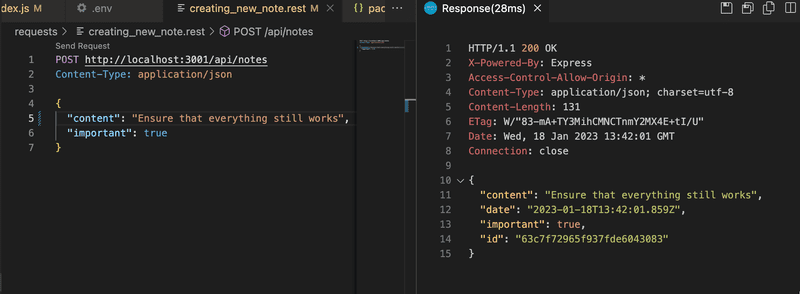
Somente depois de verificar se tudo funciona no backend, é uma boa ideia testar se o frontend funciona com o backend. É extremamente ineficiente testar as funcionalidades exclusivamente pelo frontend.
Sempre é uma boa ideia integrar tanto ao frontend quanto ao backend uma funcionalidade de cada vez. Primeiro, poderíamos implementar a busca de todas as notas no banco de dados e testá-la por meio do endpoint do backend no navegador. Após, verificaríamos se o frontend funciona com o novo backend. Depois que tudo parecer estar funcionando, passaríamos para a próxima funcionalidade. Nota dos tradutores: objetivamente, dentro do conceito de API, um endpoint é o endereço URL que identifica e acessa um recurso específico. Leia mais aqui.
Uma vez que um banco de dados é introduzido nessa mistura, é sempre útil inspecionar o estado persistido no banco de dados através, por exemplo, do painel de controle do MongoDB Atlas. Muitas vezes, pequenos programas auxiliares do Node como o mongo.js que escrevemos anteriormente podem ser muito úteis durante o desenvolvimento.
Você pode encontrar o código da nossa aplicação atual na íntegra na branch part3-4 deste repositório do GitHub.
Gerenciamento de erros
Se tentarmos visitar a URL de uma nota com um ID que não existe, por exemplo http://localhost:3001/api/notes/5c41c90e84d891c15dfa3431, onde 5c41c90e84d891c15dfa3431 não é um ID armazenado no banco de dados, a resposta será null.
Vamos mudar esse comportamento para que, se uma nota com o ID fornecido não existir, o servidor responda à requisição com o código de status HTTP "404 not found" (404 não encontrado(a)). Além disso, vamos implementar um simples bloco catch para lidar com casos em que a promessa retornada pelo método findById é rejeitada:
app.get('/api/notes/:id', (request, response) => {
Note.findById(request.params.id)
.then(note => {
if (note) { response.json(note) } else { response.status(404).end() } })
.catch(error => { console.log(error) response.status(500).end() })})Se nenhum objeto correspondente for encontrado no banco de dados, o valor de note será null e o bloco else será executado. Isso resulta em uma resposta com o código de status 404 not found (404 não encontrado(a)). Se uma promessa retornada pelo método findById for rejeitada, a resposta terá o código de status 500 internal server error (500 erro interno do servidor). O console exibe informações mais detalhadas sobre o erro.
Além da nota inexistente, há mais uma situação de erro que precisa ser lidada. Nessa situação, estamos tentando buscar uma nota com o tipo errado de id, ou seja, um id que não corresponde ao formato de identificador do Mongo.
Se fizermos a seguinte requisição, obteremos a mensagem de erro mostrada abaixo:
Method: GET
Path: /api/notes/someInvalidId
Body: {}
---
{ CastError: Cast to ObjectId failed for value "someInvalidId" at path "_id"
at CastError (/Users/mluukkai/opetus/_fullstack/osa3-muisiinpanot/node_modules/mongoose/lib/error/cast.js:27:11)
at ObjectId.cast (/Users/mluukkai/opetus/_fullstack/osa3-muisiinpanot/node_modules/mongoose/lib/schema/objectid.js:158:13)
...Dado um ID mal formatado como argumento, o método findById lançará um erro, fazendo com que a promessa retornada seja rejeitada. Isso fará com que a função callback definida no bloco catch seja chamada.
Vamos fazer alguns pequenos ajustes de resposta no bloco catch:
app.get('/api/notes/:id', (request, response) => {
Note.findById(request.params.id)
.then(note => {
if (note) {
response.json(note)
} else {
response.status(404).end()
}
})
.catch(error => {
console.log(error)
response.status(400).send({ error: 'malformatted id' }) })
})Se o formato do ID estiver incorreto, o gerenciador de erro definido no bloco catch será chamado. O código de status apropriado para o erro é 400 Bad Request (400 requisição inválida), porque a situação se encaixa perfeitamente na descrição:
A requisição não pôde ser entendida pelo servidor devido a uma sintaxe mal formatada. O cliente NÃO DEVE repetir a requisição sem modificações.
Também adicionamos alguns dados à resposta para esclarecer a causa do erro.
Ao lidar com Promessas, quase sempre é uma boa ideia adicionar gerenciamento de erro e exceção. Caso contrário, você se encontrará lidando com bugs estranhos.
Nunca é uma má ideia imprimir o objeto que causou a exceção no console do gerenciador de erro:
.catch(error => {
console.log(error) response.status(400).send({ error: 'malformatted id' })
})A razão pela qual o gerenciador de erro é chamado pode ser algo completamente diferente do que você havia imaginado. Se você imprimir o erro no console, poderá se salvar de longas e frustrantes sessões de depuração. Além disso, a maioria dos serviços modernos onde você implanta sua aplicação suporta algum tipo de sistema de registro (logging system) que se pode usar para verificar esses logs. Como já mencionado, o Heroku é um deles.
Toda vez que você trabalha em um projeto com um backend, é crucial ficar de olho na saída do console do backend. Se você está usando uma tela pequena, já é suficiente ver apenas um pedacinho da tela de saída em segundo plano. Qualquer mensagem de erro chamará sua atenção mesmo quando o console estiver bem escondido:
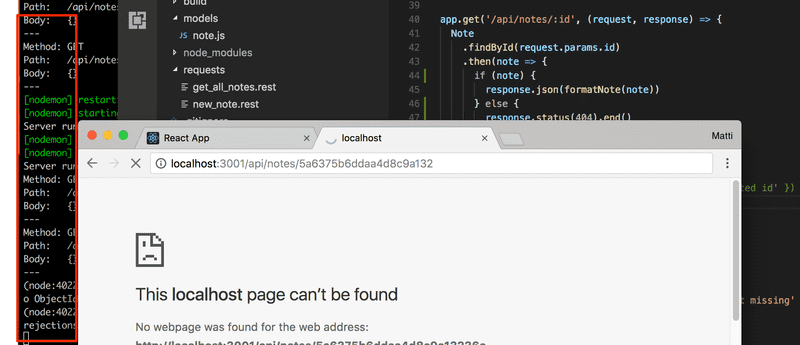
Transferindo o gerenciamento de erro para um middleware
Escrevemos o código do gerenciador de erro junto ao restante do código. Pode até ser uma solução razoável às vezes, mas há casos em que é melhor implementar todo o gerenciamento de erro em um único lugar. Isso pode ser particularmente útil se quisermos relatar dados relacionados a erros para um sistema externo de rastreamento de erros (external error-tracking system) como o Sentry posteriormente.
Vamos mudar o gerenciador para a rota /api/notes/:id para que ele passe o erro adiante com a função next. A função next é passada para o gerenciador como o terceiro parâmetro:
app.get('/api/notes/:id', (request, response, next) => { Note.findById(request.params.id)
.then(note => {
if (note) {
response.json(note)
} else {
response.status(404).end()
}
})
.catch(error => next(error))})O erro que é passado adiante é devido à função next como parâmetro. Se next for chamada sem um parâmetro, então a execução simplesmente avançará para a próxima rota ou middleware. Se a função next for chamada com um parâmetro, então a execução continuará para o middleware de gerenciamento de erro.
Os gerenciadores de erro do Express são middlewares definidos com uma função que aceita quatro parâmetros. Nosso gerenciador de erro é assim:
const errorHandler = (error, request, response, next) => {
console.error(error.message)
if (error.name === 'CastError') {
return response.status(400).send({ error: 'malformatted id' })
}
next(error)
}
// Este deve ser o último middleware a ser carregado.
app.use(errorHandler)O gerenciador de erro verifica se o erro é uma exceção CastError (grosso modo, "ErroDeLançamento"), caso em que sabemos que o erro foi causado por um id de objeto inválido para o Mongo. Nessa situação, o gerenciador de erro enviará uma resposta ao navegador com o objeto de resposta passado como parâmetro. Em todas as outras situações de erro, o middleware passa o erro para o gerenciador de erro padrão do Express.
Observe que o middleware de gerenciamento de erro deve ser o último middleware a ser carregado!
A ordem de carregamento dos middlewares
A ordem de execução dos middlewares é a mesma que a ordem em que são carregados no Express com a função app.use. Por esse motivo, é importante ter cuidado ao definir os middlewares.
A ordem correta é a seguinte:
app.use(express.static('build'))
app.use(express.json())
app.use(requestLogger)
app.post('/api/notes', (request, response) => {
const body = request.body
// ...
})
const unknownEndpoint = (request, response) => {
response.status(404).send({ error: 'unknown endpoint' })
}
// gerenciador de requisições com um endpoint desconhecido
app.use(unknownEndpoint)
const errorHandler = (error, request, response, next) => {
// ...
}
// gerenciador de requisições com um resultado para erros
app.use(errorHandler)O middleware JSON-parser ("analisador de JSON") deve estar entre os primeiros middlewares carregados no Express. Se a ordem fosse a seguinte...
app.use(requestLogger) // request.body torna-se indefinido!
app.post('/api/notes', (request, response) => {
// request.body torna-se indefinido!
const body = request.body
// ...
})
app.use(express.json())... os dados JSON enviados com as requisições HTTP não estariam disponíveis para o middleware de registro (logger middleware) ou para o gerenciador da rota POST, já que o request.body estaria indefinido nesse ponto.
Também é importante que o middleware que gerencia rotas não suportadas esteja próximo ao último middleware que é carregado no Express, logo antes do gerenciador de erro.
Por exemplo, a seguinte ordem de carregamento causaria um problema:
const unknownEndpoint = (request, response) => {
response.status(404).send({ error: 'unknown endpoint' })
}
// gerenciador de requisições com endpoint desconhecido
app.use(unknownEndpoint)
app.get('/api/notes', (request, response) => {
// ...
})Dessa forma, o gerenciamento de endpoints desconhecidos é posto em ordem antes do gerenciador de requisições HTTP. Como o gerenciador de endpoints desconhecidos responde a todas as requisições com 404 unknown endpoint (404 endpoint desconhecido), nenhuma rota ou middleware será chamado após a resposta ter sido enviada pelo middleware de endpoint desconhecido. A única exceção a isso é o gerenciador de erros, que precisa vir no final, após o gerenciador de endpoints desconhecidos.
Outras operações
Vamos adicionar algumas funcionalidades restantes à nossa aplicação, incluindo a exclusão e a atualização de uma nota individual.
A maneira mais fácil de excluir uma nota do banco de dados é com o método findByIdAndDelete (grosso modo, "acharPorIdERemover"):
app.delete('/api/notes/:id', (request, response, next) => {
Note.findByIdAndDelete(request.params.id)
.then(result => {
response.status(204).end()
})
.catch(error => next(error))
})Em ambos os casos "bem-sucedidos" de exclusão de um recurso, o backend responde com o código de status 204 no content (204 sem conteúdo). Os dois casos diferentes são: (1) excluir uma nota que existe; e (2) excluir uma nota que não existe no banco de dados. O parâmetro de retorno result poderia ser usado para verificar se um recurso foi realmente excluído, e poderíamos usar essa informação para retornar diferentes códigos de status para os dois casos, caso julgássemos necessário. Qualquer exceção que venha a ocorrer é lançada ao gerenciador de erro.
A alternância da importância de uma nota pode ser facilmente realizada com o método findByIdAndUpdate (grosso modo, "acharPorIdEAtualizar").
app.put('/api/notes/:id', (request, response, next) => {
const body = request.body
const note = {
content: body.content,
important: body.important,
}
Note.findByIdAndUpdate(request.params.id, note, { new: true })
.then(updatedNote => {
response.json(updatedNote)
})
.catch(error => next(error))
})No código acima, também permitimos a edição do conteúdo da nota.
Observe que o método findByIdAndUpdate recebe um objeto JavaScript comum como parâmetro, e não um novo objeto de nota criado com a função construtora Note.
Existe um detalhe importante em relação ao uso do método findByIdAndUpdate. Por padrão, o parâmetro updatedNote do gerenciador de evento recebe o documento original sem as modificações. Adicionamos o parâmetro opcional { new: true }, que fará com que nosso gerenciador de evento seja chamado com o novo documento modificado em vez do original.
Após testar o backend diretamente com o Postman e o cliente REST do VS Code, podemos verificar que parece funcionar. O frontend também parece funcionar com o backend usando o banco de dados.
É possível encontrar o código da nossa aplicação atual na íntegra na branch part3-5 neste repositório do GitHub.
Juramento de um Verdadeiro Programador Full Stack
Chegou novamente a hora dos exercícios. A complexidade de nossa aplicação cresceu pois, além do frontend e do backend, também temos um banco de dados. Há de fato muitas fontes potenciais de erros.
Portanto, devemos estender novamente nosso juramento:
Desenvolvimento Full Stack é algo extremamente difícil, e é por isso que eu usarei todos os meios possíveis para torná-lo mais fácil:
- Eu manterei meu Console do navegador sempre aberto;
- Eu usarei a guia Rede das Ferramentas do Desenvolvedor do navegador para garantir que o frontend e o backend estejam se comunicando da forma que eu planejei;
- Eu ficarei de olho no estado do servidor para garantir que os dados enviados pelo frontend estejam sendo salvos lá da forma que eu planejei;
- Eu ficarei de olho no banco de dados: o backend salva os dados no banco de dados no formato correto? ;
- Eu vou progredir aos poucos, passo a passo;
- Eu escreverei muitas instruções console.log para ter certeza de que estou entendendo como o código se comporta e para me ajudar a identificar os erros;
- Se meu código não funcionar, não escreverei mais nenhuma linha no código. Em vez disso, começarei a excluir o código até que funcione ou retornarei ao estado em que tudo ainda estava funcionando; e
- Quando eu pedir ajuda no canal do Discord do curso ou em outro lugar, formularei minhas perguntas de forma adequada. Veja aqui como pedir ajuda.
Exercícios 3.15 a 3.18
3.15: Phonebook database — 3º passo
Altere o backend para que a exclusão de entradas da lista telefônica seja refletida no banco de dados.
Verifique se o frontend ainda funciona após as alterações.
3.16: Phonebook database — 4º passo
Transfira o gerenciamento de erros da aplicação para um novo middleware gerenciador de erros.
3.17*: Phonebook database — 5º passo
Se o usuário tentar criar uma nova entrada na lista telefônica para uma pessoa cujo nome já está presente na lista, o frontend tentará atualizar o número de telefone da entrada existente fazendo uma requisição HTTP PUT para a URL única da entrada.
Modifique o backend para suportar essa requisição.
Verifique se o frontend funciona após fazer suas alterações.
3.18*: Phonebook database — 6º passo
Atualize também o gerenciamento das rotas api/persons/:id e info para usar o banco de dados e verifique se elas funcionam diretamente com o navegador, com o Postman ou com o cliente REST do VS Code.
A verificação no navegador de uma entrada individual da lista telefônica deve ocorrer da seguinte maneira:
