b
Fundamentos de aplicações web
Antes de começarmos a programar, passaremos por alguns princípios de desenvolvimento web examinando uma aplicação de exemplo em https://studies.cs.helsinki.fi/exampleapp.
A aplicação serve apenas para demonstrar alguns conceitos básicos do curso e, de maneira alguma, é um exemplo de como uma aplicação web moderna deve ser feita. Pelo contrário, ela demonstra algumas técnicas antigas de desenvolvimento web, que até poderiam ser consideradas como práticas ruins hoje em dia.
O código seguirá as melhores práticas contemporâneas a partir da parte 1 em diante.
Abra a aplicação de exemplo em seu navegador. Às vezes demora um pouco.
O conteúdo do curso é feito utilizando o navegador Chrome.
A 1ª regra de desenvolvimento web: Mantenha sempre o "Console do Desenvolvedor" aberto em seu navegador web. No macOS, abra o console pressionando F12 ou option-cmd-i simultaneamente. No Windows ou Linux, abra o console pressionando F12 ou ctrl-shift-i simultaneamente. O console também pode ser aberto via tecla Menu.
Lembre-se de sempre manter o console do desenvolvedor aberto ao desenvolver aplicações web.
O console do desenvolvedor é mais ou menos assim:
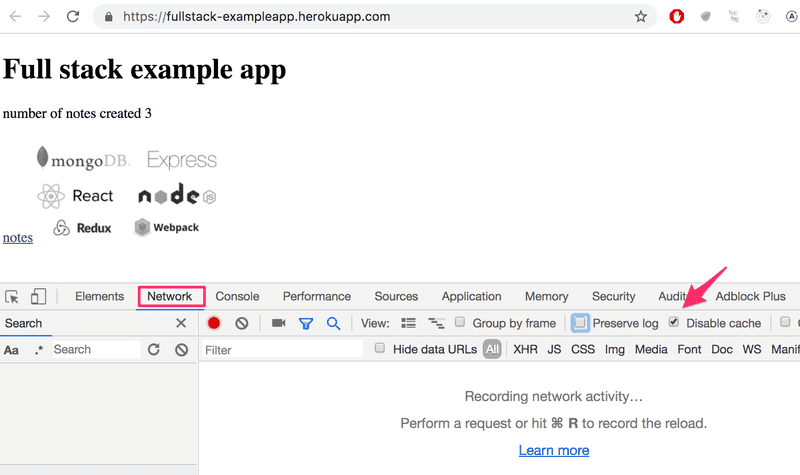
Certifique-se de que a guia Rede (Network) do navegador esteja aberta e marque a opção Desativar cache (Disable cache) conforme mostrado. Preservar registro (Preserve log) também pode ser útil: ele salva os logs impressos pela aplicação quando a página é recarregada.
Obs.: A guia mais importante é a Console. No entanto, nesta introdução, usaremos mais a guia Rede (Network).
HTTP GET
O servidor e o navegador web se comunicam usando o protocolo HTTP. A guia Rede mostra como o navegador e o servidor se comunicam.
Quando você recarrega a página (pressione a tecla F5 ou o símbolo ↻ em seu navegador), o console mostrará que dois eventos aconteceram:
- O navegador baixou o conteúdo da página studies.cs.helsinki.fi/exampleapp do servidor; e
- E baixou a imagem kuva.png.
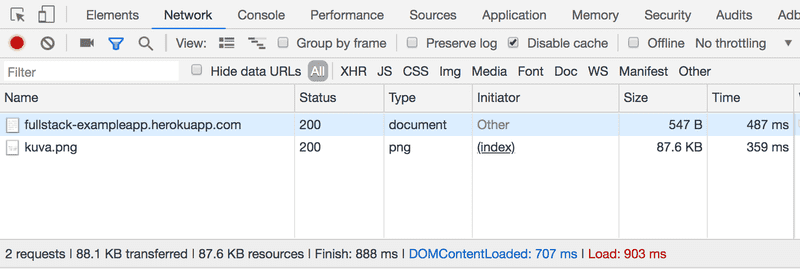
Se estiver utilizando um monitor pequeno, terá que ampliar a janela do console para conseguir ver claramente.
Ao clicar no primeiro evento, mais informações sobre o que está acontecendo são reveladas:
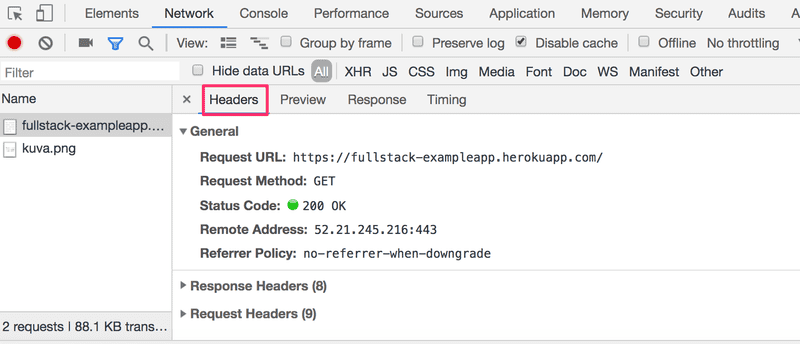
Na parte superior, Geral (General), mostra que o navegador requisitou o endereço https://studies.cs.helsinki.fi/exampleapp usando o método GET (embora o endereço tenha mudado ligeiramente desde que esta imagem foi feita) e que a requisição foi bem-sucedida, pois o servidor respondeu com o código de status 200.
A requisição e a resposta do servidor possuem vários cabeçalhos (headers):
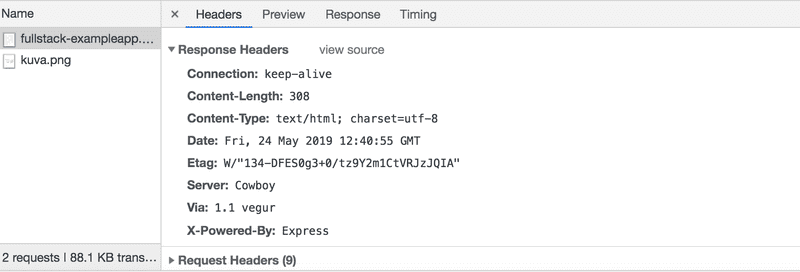
Os cabeçalhos de resposta no topo nos dizem, por exemplo, o tamanho da resposta em bytes e o momento exato da resposta. Um cabeçalho importante, Content-Type, nos diz que a resposta é um arquivo de texto no formato utf-8 e que os conteúdos foram formatados em HTML. Dessa forma, o navegador sabe que a resposta é uma página HTML comum e a renderiza para o navegador "como uma página web".
A guia Resposta (Response) mostra os dados de resposta, uma página HTML comum. A seção body determina a estrutura da página renderizada na tela:
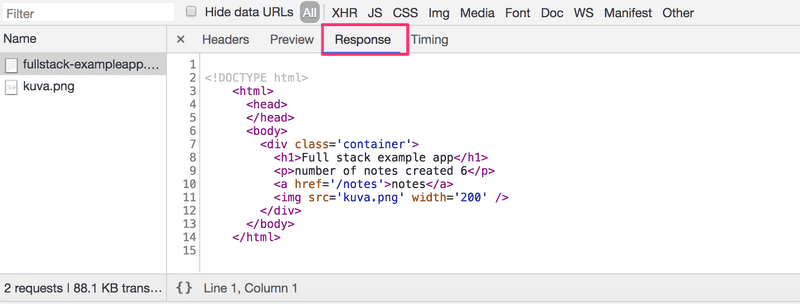
A página contém um elemento div, que por sua vez contém um título, um link para a página notes e uma tag img, e exibe o número de notas criadas.
Devido à tag "img", o navegador faz uma segunda requisição HTTP para buscar a imagem kuva.png do servidor. Os detalhes da requisição são os seguintes:
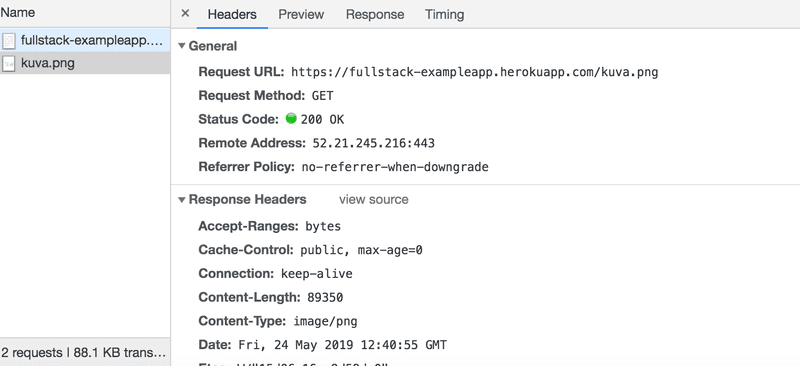
A requisição foi feita para o endereço https://studies.cs.helsinki.fi/exampleapp/kuva.png e o seu tipo é HTTP GET. Os cabeçalhos de resposta (response headers) nos dizem que o tamanho da resposta é 89350 bytes e seu Content-type é image/png, então é uma imagem png. O navegador usa essa informação para renderizar a imagem corretamente na tela.
{kind=link}
O encadeamento de eventos causado pela abertura da página https://studies.cs.helsinki.fi/exampleapp no navegador forma o seguinte diagrama de sequência:

O diagrama de sequência demonstra como o navegador e o servidor estão se comunicando ao longo do tempo. O tempo flui no diagrama de cima para baixo, então se inicia com a primeira requisição que o navegador envia ao servidor, seguido pela resposta.
Primeiro, o navegador envia uma requisição HTTP GET ao servidor para buscar o código HTML da página. A tag img no HTML requisita que o navegador busque a imagem kuva.png. O navegador renderiza a página HTML e a imagem na tela.
Embora seja difícil notar, a página HTML começa a ser renderizada antes que a imagem tenha sido buscada do servidor.
Aplicações web tradicionais
A página inicial da aplicação de exemplo funciona como uma aplicação web tradicional. Ao entrar na página, o navegador busca o documento HTML que detalha a estrutura e o conteúdo textual da página no servidor.
O servidor formou esse documento de alguma forma. O documento pode ser um arquivo de texto estático salvo no diretório do servidor. O servidor também pode formar os documentos HTML dinamicamente de acordo com o código da aplicação, utilizando, por exemplo, dados de um banco de dados. O código HTML da aplicação de exemplo foi formado dinamicamente porque contém informações sobre o número de notas criadas.
O código HTML da página inicial é o seguinte:
const getFrontPageHtml = noteCount => {
return `
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<div class='container'>
<h1>Exemplo de aplicação Full Stack</h1>
<p>Número de notas criadas: ${noteCount}</p>
<a href='/notes'>notes</a>
<img src='kuva.png' width='200' />
</div>
</body>
</html>
`
}
app.get('/', (req, res) => {
const page = getFrontPageHtml(notes.length)
res.send(page)
})Você não precisa entender o código agora.
O conteúdo da página HTML foi salvo como uma string-modelo ou uma string que permite avaliar, por exemplo, variáveis dentro dela. A parte da página inicial que muda dinamicamente, o número de notas salvas (no código noteCount), é substituída pelo número atual de notas (no código notes.length) na string de modelo.
Escrever HTML no meio do código não é algo interessante de se fazer, mas para os programadores PHP antigos, isso era uma prática normal.
Em aplicações web tradicionais, o navegador é "burro". Ele só busca dados HTML do servidor e toda a lógica da aplicação está no servidor. Um servidor pode ser criado usando Java Spring, Python Flask ou Ruby on Rails, para citar apenas alguns exemplos.
O exemplo usa a biblioteca Express com Node.js. Este curso usará Node.js e Express para criar servidores web.
Executando a lógica da aplicação no navegador
Mantenha o Console do Desenvolvedor aberto. Esvazie o console clicando no símbolo 🚫 ou digitando clear() no console. Agora, quando você for para a página notes, o navegador fará 4 (quatro) requisições HTTP:
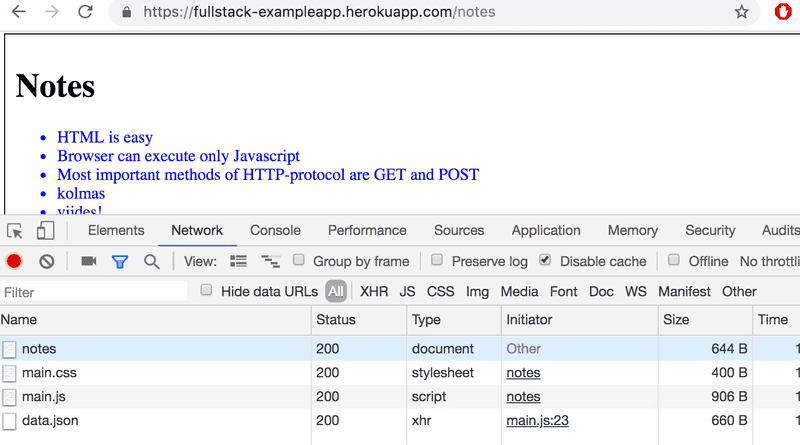
Todas as requisições têm tipos diferentes. O tipo da primeira requisição é document. É o código HTML da página, e ele é assim:
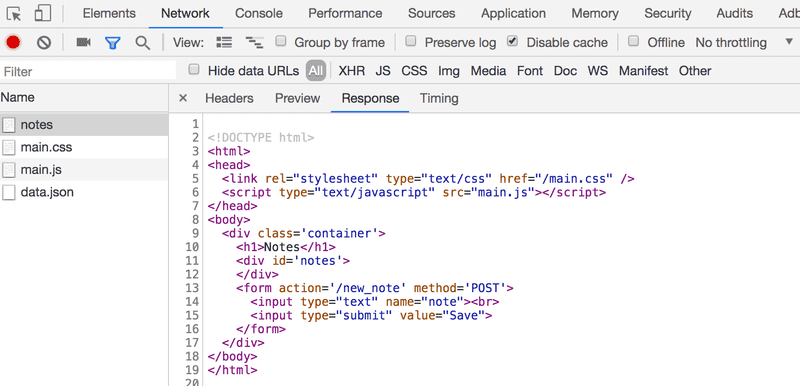
Quando comparamos a página mostrada no navegador e o código HTML retornado pelo servidor, notamos que o código não contém a lista de notas. A seção head do HTML contém uma tag script, que faz com que o navegador busque um arquivo JavaScript chamado main.js.
O código JavaScript fica assim:
var xhttp = new XMLHttpRequest()
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
const data = JSON.parse(this.responseText)
console.log(data)
var ul = document.createElement('ul')
ul.setAttribute('class', 'notes')
data.forEach(function(note) {
var li = document.createElement('li')
ul.appendChild(li)
li.appendChild(document.createTextNode(note.content))
})
document.getElementsByClassName('notes').appendChild(ul)
}
}
xhttp.open('GET', '/data.json', true)
xhttp.send()Os detalhes do código não são importantes agora, mas algum código foi incluído para dar vida às imagens e ao texto. Começaremos a programar de verdade na parte 1. O código-exemplo nesta parte, na realidade, não tem relação alguma com as técnicas de programação deste curso.
Alguns podem se perguntar o porquê do objeto "xhttp" ser usado aqui em vez do moderno "fetch" ("buscar" ou "ir buscar"). Isso se deve ao fato de não querermos entrar no assunto das "Promises" (promessas) ainda, e o código ter um papel secundário nesta parte. Voltaremos às formas modernas de fazer requisições ao servidor na Parte 2.
Imediatamente após baixar a tag script, o navegador começa a executar o código.
As últimas duas linhas instruem o navegador a fazer uma requisição HTTP GET ao endereço do servidor /data.json:
xhttp.open('GET', '/data.json', true)
xhttp.send()Esta é a requisição mais "profunda" exibida na guia de Rede.
Podemos tentar ir ao endereço https://studies.cs.helsinki.fi/exampleapp/data.json diretamente do navegador:

Lá encontramos as notas em formato de "dados brutos" JSON. Por padrão, os navegadores baseados em Chromium não são muito bons em exibir dados JSON. É possível usar plugins para lidar com a formatação. Instale, por exemplo, a extensão JSONVue no Chrome e recarregue a página. Os dados agora estão formatados corretamente:
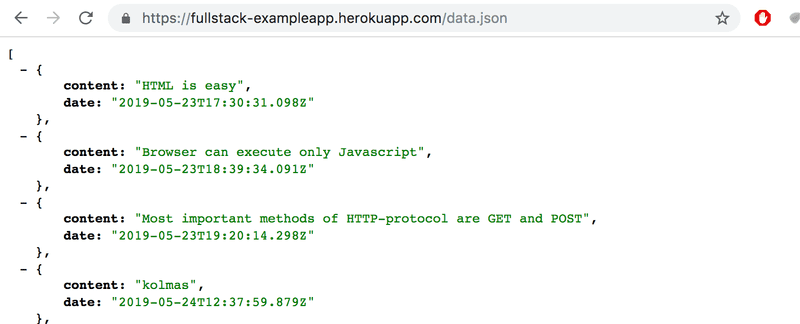
Então, o código JavaScript da página de notas ilustrada acima baixa os dados JSON contendo as notas e forma uma lista de itens de notas a partir do seu conteúdo:
Isso é feito pelo seguinte código:
const data = JSON.parse(this.responseText)
console.log(data)
var ul = document.createElement('ul')
ul.setAttribute('class', 'notes')
data.forEach(function(note) {
var li = document.createElement('li')
ul.appendChild(li)
li.appendChild(document.createTextNode(note.content))
})
document.getElementById('notes').appendChild(ul)O código cria primeiro uma lista não ordenada com a tag ul...
var ul = document.createElement('ul')
ul.setAttribute('class', 'notes')...e em seguida, adiciona uma tag li para cada nota. Somente o campo content de cada nota se torna o conteúdo da tag li. Os "timestamps" (registros de data/hora) encontrados nos dados JSON não são utilizados para nada neste caso.
data.forEach(function(note) {
var li = document.createElement('li')
ul.appendChild(li)
li.appendChild(document.createTextNode(note.content))
})Abra a guia Console no seu Console do Desenvolvedor:

Ao clicar no pequeno triângulo no início da linha, você expande o texto na guia Console.
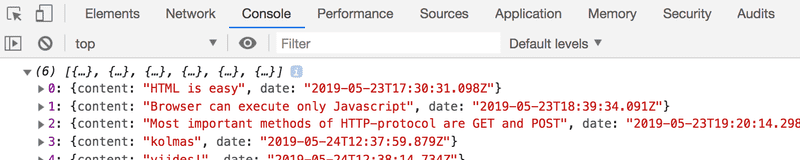
Esse "output" (saída) no console é fruto do comando console.log no código:
const data = JSON.parse(this.responseText)
console.log(data)Então, após receber os dados do servidor, o código os imprime no console.
Você se familiarizará com a guia Console e o comando console.log no decorrer do curso.
Gerenciadores de Evento (Event handlers) e Funções Callback
A estrutura desse código é um pouco estranha:
var xhttp = new XMLHttpRequest()
xhttp.onreadystatechange = function() {
// código que lida com a resposta do servidor
}
xhttp.open('GET', '/data.json', true)
xhttp.send()A requisição ao servidor é feita na última linha, mas o código que lida com a resposta é encontrado mais acima. O que está acontecendo?
xhttp.onreadystatechange = function () {Nessa linha, um event handler ("gerenciador de evento" ou "manipulador de evento") para o evento onreadystatechange é definido para o objeto xhttp que faz a requisição. Quando o estado do objeto muda, o navegador chama a função gerenciadora de evento. O código da função verifica que o readyState é igual a 4 (o que representa o estado "DONE" que exibe a descrição A operação está completa) e que o código de status HTTP da resposta é 200.
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
// código que gerencia a resposta do servidor
}
}O mecanismo de chamada de gerenciadores de eventos é muito comum em JavaScript. As funções de gerência de eventos são chamadas de funções callback (funções de retorno de chamada). O código da aplicação não chama as funções em si, mas o "runtime environment" (ambiente de tempo de execução) — isto é, o navegador, que chama a função no tempo correto quando o evento acontece.
Modelo de Documento por Objetos (DOM [Document Object Model])
Podemos pensar em páginas HTML como estruturas implícitas de uma árvore.
html
head
link
script
body
div
h1
div
ul
li
li
li
form
input
inputA mesma estrutura de árvore pode ser vista na guia Elementos do console.
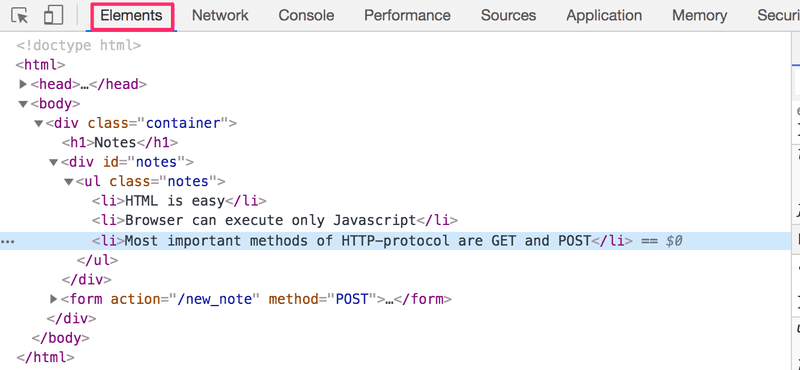
O funcionamento do navegador baseia-se na ideia de representar os elementos HTML como uma árvore.
O Modelo de Documento por Objetos, ou DOM, é uma API (Application Programming Interface), isto é uma Interface de Programação de Aplicação, que possibilita a modificação programática das árvores de elementos correspondentes às páginas web.
O código JavaScript introduzido no capítulo anterior usou a API DOM para adicionar uma lista de notas na página.
O código a seguir cria um novo nó (node) na variável ul e adiciona alguns nós-filho a ele:
var ul = document.createElement('ul')
data.forEach(function(note) {
var li = document.createElement('li')
ul.appendChild(li)
li.appendChild(document.createTextNode(note.content))
})Por fim, a ramificação da árvore da variável ul é conectada ao seu lugar previsto na árvore HTML da página:
document.getElementsByClassName('notes').appendChild(ul)Gerenciando o objeto "Document" por meio do console
O nó de nível mais alto da árvore DOM de um documento HTML é o objeto document. Podemos realizar várias operações em uma página web usando a API DOM. Você consegue acessar o objeto document digitando document na guia Console:
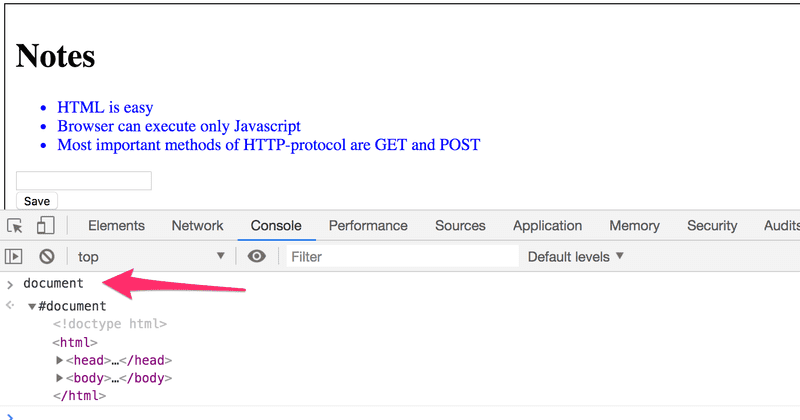
Vamos adicionar uma nova nota à página a partir do console.
Primeiro, vamos pegar a lista de notas da página. A lista está no primeiro elemento "ul" da página:
list = document.getElementsByTagName('ul')[0]Em seguida, criamos um novo elemento "li" e adicionamos algum conteúdo de texto a ele:
newElement = document.createElement('li')
newElement.textContent = 'Page manipulation from console is easy'E adicionamos o novo elemento "li" à lista:
list.appendChild(newElement)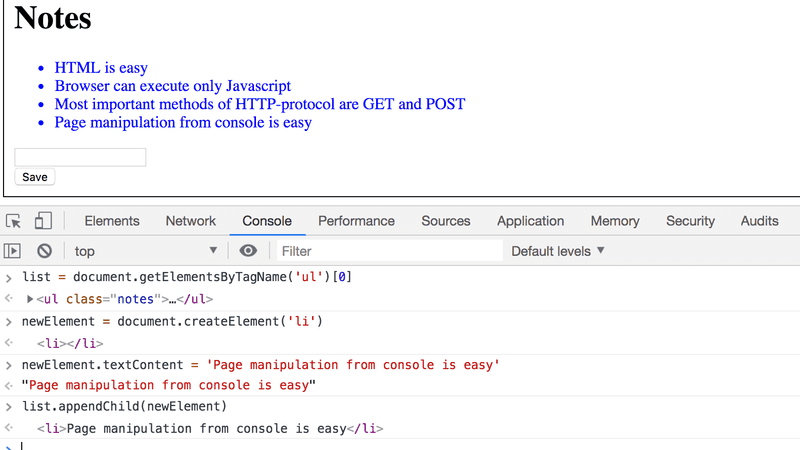
Mesmo que a página seja atualizada no seu navegador, as mudanças não são permanentes. Se a página for recarregada, a nova nota desaparecerá, pois as mudanças não foram enviadas ao servidor. O código JavaScript que o navegador busca sempre criará a lista de notas com base nos dados JSON do endereço https://studies.cs.helsinki.fi/exampleapp/data.json.
CSS
O elemento head (cabeçalho) do código HTML da página Notes contém uma tag link, que determina que o navegador deve buscar uma folha de estilo CSS a partir do endereço main.css.
CSS (Cascading Style Sheets - folhas de estilo em cascata), é uma linguagem de estilo usada para determinar a aparência de páginas web.
O arquivo CSS baixado é o seguinte:
.container {
padding: 10px;
border: 1px solid;
}
.notes {
color: blue;
}O arquivo define dois seletores de classe. Eles são utilizados para selecionar certas partes da página e para definir regras de estilo para estilizá-las.
Uma definição de seletor de classe sempre começa com um ponto e contém o nome da classe.
As classes são atributos, que podem ser adicionados à elementos HTML.
Atributos CSS podem ser examinados na guia Elementos (Elements):
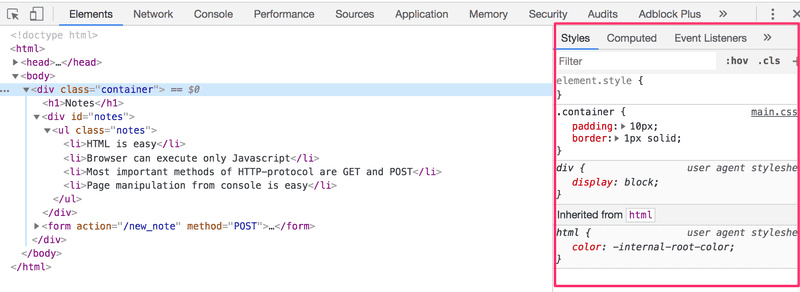
O elemento div mais externo tem a classe container. O elemento ul que contém a lista de notas tem a classe notes.
A primeira regra CSS define que elementos com a classe container terão a borda da largura de um pixel. Ele também define um padding de 10 pixels no elemento. Essa propriedade adiciona um espaço vazio entre o conteúdo do elemento e a borda.
A segunda regra CSS define a cor do texto das notas como azul.
Os elementos HTML também podem ter outros atributos além de classes. O elemento div, que contém as notas, tem um atributo id (identificador[exclusivo]). O código JavaScript usa o "id" para encontrar o elemento.
A guia Elementos (Elements) do console pode ser usada para alterar os estilos dos elementos.
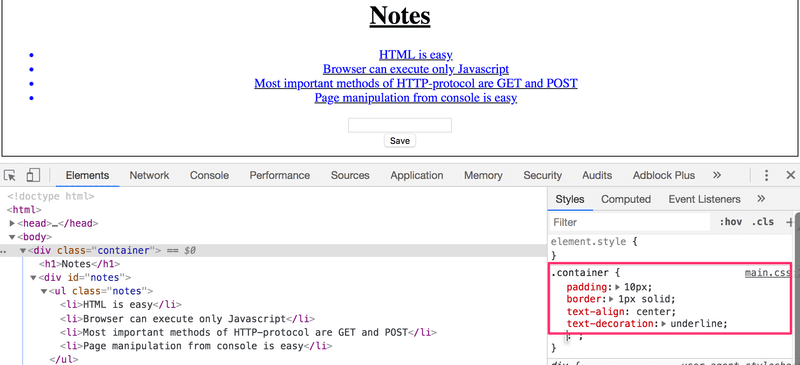
As alterações feitas no console não serão permanentes. Se deseja fazer alterações duradouras, elas devem ser salvas na folha de estilo CSS no servidor.
Carregando uma página contendo JavaScript — revisão
Vamos revisar o que acontece quando a página https://studies.cs.helsinki.fi/exampleapp/notes é aberta no navegador.
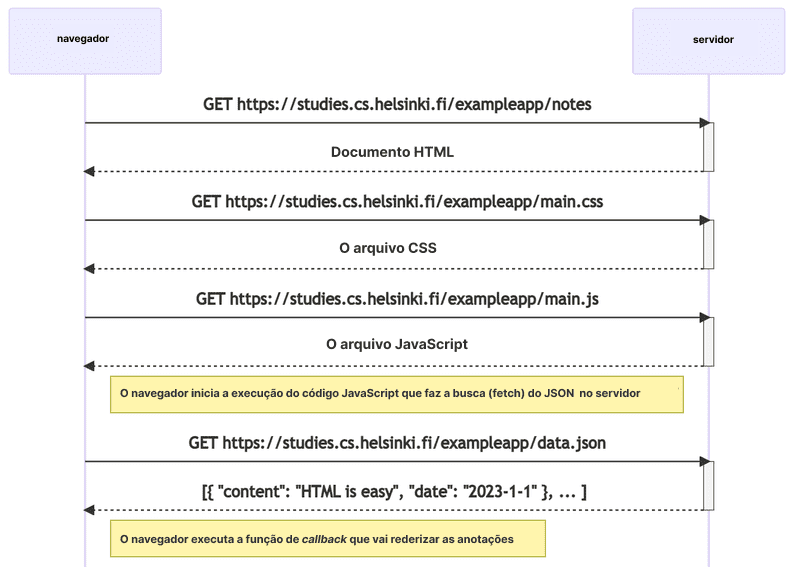
- O navegador busca o código HTML que define o conteúdo e a estrutura da página do servidor usando uma requisição HTTP GET;
- Os links no código HTML fazem com que o navegador também busque a folha de estilo CSS main.css...
- ...e um arquivo de código JavaScript main.js;
- O navegador executa o código JavaScript. O código faz uma requisição HTTP GET para o endereço https://studies.cs.helsinki.fi/exampleapp/data.json, que retorna as notas como dados JSON; e
- Quando é finalizada a busca pelos dados, o navegador executa um event handler, que renderiza as notas na página usando a API DOM.
Formulários (Forms) e HTTP POST
Agora, vamos examinar como se adiciona uma nova nota.
A página de notas contém um elemento formulário (form).
Quando o botão no formulário é clicado, o navegador envia a entrada (input) do usuário para o servidor. Vamos abrir a guia Rede (Network) e ver como se envia o formulário:
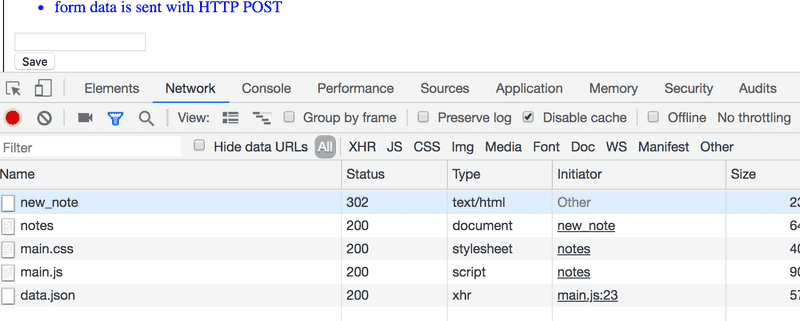
Surpreendentemente, o envio do formulário gera não menos que cinco requisições HTTP. A primeira é o evento de envio do formulário. Vamos focar nessa parte:
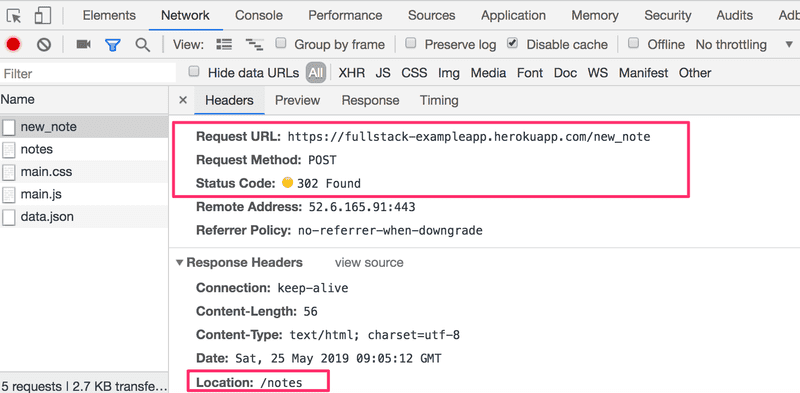
Trata-se de uma requisição HTTP POST para o endereço do servidor newnote. O servidor responde com o código de status HTTP 302. Isso é um [redirecionamento de URL](https://en.wikipedia.org/wiki/URLredirection), no qual o servidor pede ao navegador para fazer uma nova requisição HTTP GET para o endereço definido no cabeçalho Localização (Location) — o endereço notes.
Então, o navegador recarrega a página de Notas (Notes). O recarregamento faz mais três requisições HTTP: busca o arquivo CSS (main.css), o arquivo de JavaScript (main.js) e os dados das notas (data.json).
A guia de Rede também mostra os dados enviados com o formulário:
Obs.: Na versão mais recente do Chrome, o menu drop-down (lista suspensa) "Form Data" está dentro da nova guia "Payload", localizada à direita da guia "Cabeçalhos".
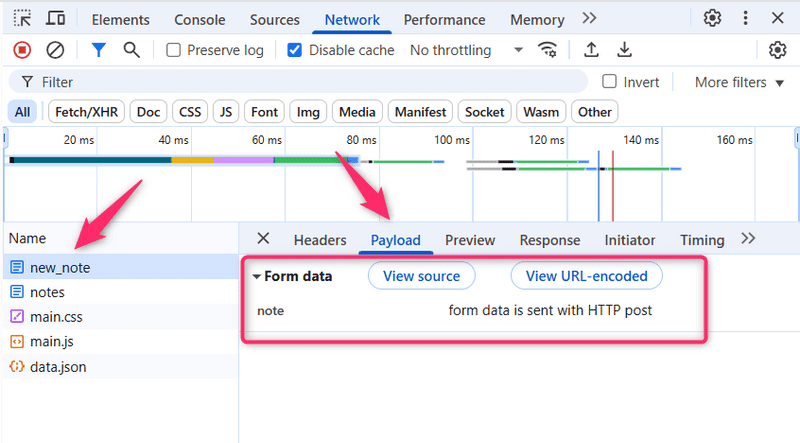
A tag Form tem os atributos action e method, que definem que o envio do formulário é feito como uma requisição HTTP POST para o endereço new_note.
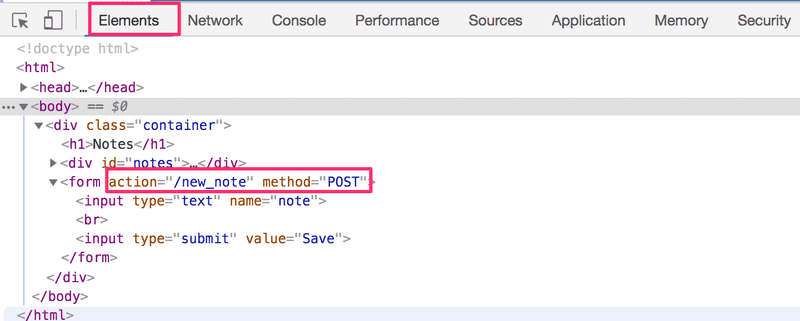
O código no servidor responsável pela requisição POST é bastante simples (Obs.: este código está no servidor, e não no código JavaScript baixado pelo navegador):
app.post('/new_note', (req, res) => {
notes.push({
content: req.body.note,
date: new Date(),
})
return res.redirect('/notes')
})Os dados são enviados como o body da requisição POST.
O servidor consegue acessar os dados acessando o campo req.body do objeto de requisição req.
O servidor cria um novo objeto nota e adiciona-o a um array chamado notes.
notes.push({
content: req.body.note,
date: new Date(),
})Os objetos de "Notes" têm dois campos: content, contendo o conteúdo real da nota; e date, contendo a data e hora em que a nota foi criada.
O servidor não salva as novas notas em um banco de dados, então elas desaparecem quando o servidor é reiniciado.
AJAX
A página "Notes", da nossa aplicação, segue um estilo de desenvolvimento web dos anos 90 e usa "Ajax". Como tal, ela está na crista da onda da tecnologia web dos anos 2000.
AJAX (Asynchronous JavaScript and XML, ou seja, JavaScript Assíncrono e XML) é um termo que foi introduzido em fevereiro de 2005 com base em avanços na tecnologia do navegador para descrever uma nova abordagem revolucionária que permitia o carregamento de conteúdo em páginas web usando JavaScript embutido dentro do HTML, sem a necessidade de re-renderizar a página.
Antes da Era AJAX, todas as páginas web funcionavam como a aplicação web tradicional que vimos anteriormente neste capítulo. Todos os dados mostrados na página eram buscados com o código HTML gerado pelo servidor.
A página "Notes" usa AJAX para buscar os dados das notas. O envio do formulário ainda usa o mecanismo tradicional de envio de formulários web.
As URLs da aplicação refletem os tempos antigos e despreocupados. Os dados JSON são buscados na URL https://studies.cs.helsinki.fi/exampleapp/data.json e novas notas são enviadas para a URL https://studies.cs.helsinki.fi/exampleapp/new_note. Hoje em dia, URLs como essas não seriam consideradas aceitáveis, pois não seguem as convenções geralmente reconhecidas de APIs RESTful (Representational State Transfer (REST) [Transferência de Estado Representacional]), que veremos com mais detalhes na parte 3.
O conceito por detrás do termo AJAX agora é tão cotidiano e básico que não se verifica nele nenhuma novidade para os dias atuais. O termo caiu no esquecimento e a nova geração nem sequer ouviu falar dele.
Single Page Application (SPA)
Em nossa aplicação de exemplo, a página inicial funciona como uma página web tradicional: toda a lógica está no servidor e o navegador só renderiza o HTML conforme instruído.
A página "Notes" transfere algumas dessas responsabilidades para o navegador, gerando o código HTML para notas que já existem. O navegador realiza essa tarefa executando o código JavaScript que ele baixou do servidor. O código baixa as notas do servidor como dados JSON e adiciona elementos HTML para exibir as notas na página usando a API DOM.
Nos últimos anos, o estilo SPA (Single Page Aplication) de criação de aplicações web surgiu. Os sites de estilo SPA não baixam todas as suas páginas separadamente do servidor como o nosso exemplo de aplicação faz, mas incluem apenas uma página HTML baixada do servidor, cujo conteúdo é manipulado com o código JavaScript que é executado no navegador.
A página "Notes" da nossa aplicação tem alguma semelhança com as aplicações de estilo SPA, mas ainda não está bem lá. Mesmo que a lógica para renderizar as notas seja executada no navegador, a página ainda usa o mecanismo tradicional de adição de novas notas. Os dados são enviados para o servidor através do envio do formulário e o servidor instrui o navegador a recarregar a página "Notes" com um redirect.
Uma versão SPA da aplicação que estamos utilizando de exemplo pode ser encontrada em https://studies.cs.helsinki.fi/exampleapp/spa. À primeira vista, a aplicação parece igual à anterior. O código HTML é quase idêntico, mas o arquivo JavaScript é diferente (spa.js), e há uma pequena mudança na maneira como a tag "form" é definida:
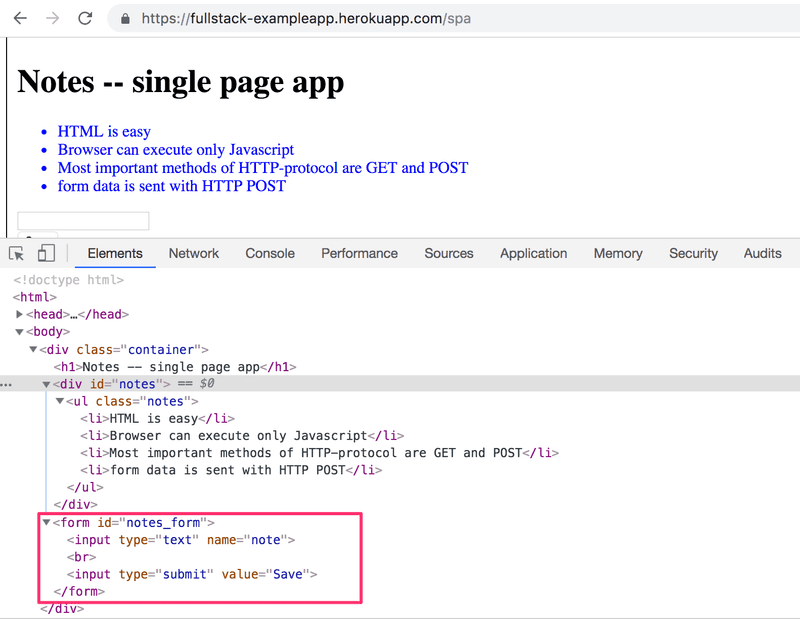
O formulário não possui atributos action ou method para definir como e onde enviar os dados de entrada.
Abra a guia Rede (Network) e esvazie-a. Quando você criar uma nova nota, verá que o navegador envia apenas uma requisição para o servidor.
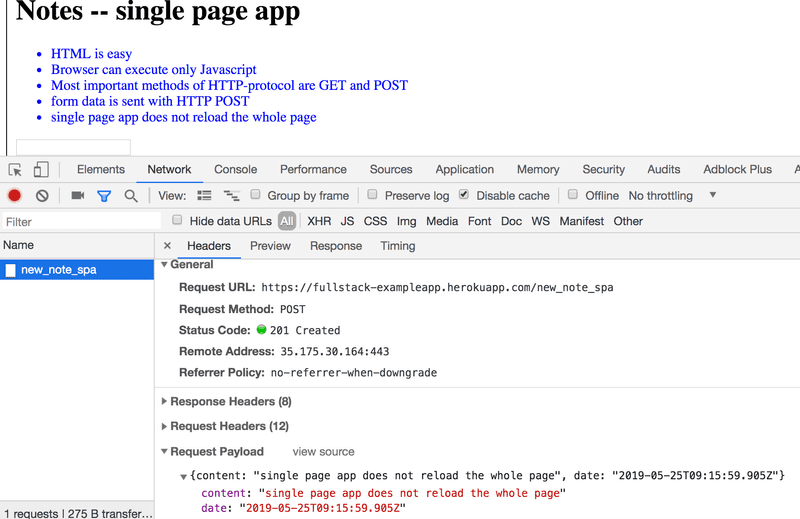
A requisição POST para o endereço new_note_spa contém a nova nota como dados JSON, contendo tanto o conteúdo da nota (content) quanto o timestamp (date):
{
content: "Uma aplicação de página única (SPA) não recarrega toda a página",
date: "2019-05-25T15:15:59.905Z"
}O cabeçalho Content-Type da requisição informa ao servidor que os dados incluídos estão representados no formato JSON.
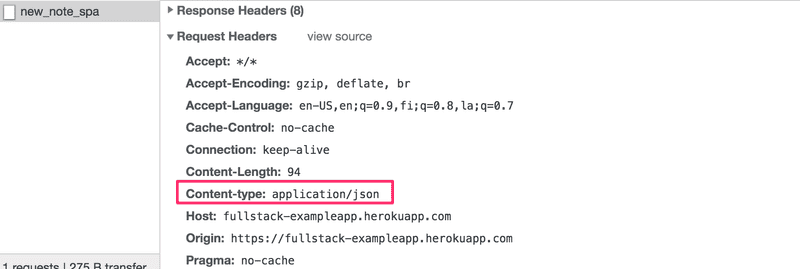
Sem esse cabeçalho, o servidor não saberia como analisar corretamente os dados.
O servidor responde com o código de status 201. Dessa vez, o servidor não requisita um redirecionamento, o navegador fica na mesma página e não envia mais requisições HTTP.
A versão SPA da nossa aplicação não envia de forma tradicional os dados do formulário, mas usa o código JavaScript que recuperou do servidor. Vamos analisar um pouco esse código, embora entender todos os detalhes dele não seja importante ainda nesta etapa.
var form = document.getElementById('notes_form')
form.onsubmit = function(e) {
e.preventDefault()
var note = {
content: e.target.elements[0].value,
date: new Date(),
}
notes.push(note)
e.target.elements[0].value = ''
redrawNotes()
sendToServer(note)
}O comando document.getElementById('notes_form') instrui o código a buscar o elemento de formulário da página e a registrar um gerenciador de evento para lidar com o evento de envio do formulário. O gerenciador de evento chama imediatamente o método e.preventDefault() para evitar o tratamento padrão do envio do formulário. O método padrão enviaria os dados para o servidor e causaria uma nova requisição GET, o que não queremos que aconteça.
Em seguida, o gerenciador de evento cria uma nova nota, adiciona-a à lista de notas com o comando notes.push(note), redesenha a lista de notas na página e envia a nova nota ao servidor.
O código para enviar a nota ao servidor é o seguinte:
var sendToServer = function(note) {
var xhttpForPost = new XMLHttpRequest()
// ...
xhttpForPost.open('POST', '/new_note_spa', true)
xhttpForPost.setRequestHeader('Content-type', 'application/json')
xhttpForPost.send(JSON.stringify(note))
}O código determina que os dados devem ser enviados com uma requisição HTTP POST e o tipo de dados deve ser JSON. O tipo de dados é determinado com um cabeçalho Content-type. Em seguida, os dados são enviados como uma string JSON.
O código da aplicação está disponível em https://github.com/mluukkai/example_app. Vale ressaltar que a aplicação serve apenas para demonstrar os conceitos do curso. O código segue um estilo ruim de desenvolvimento em algumas partes e não deve ser usado como exemplo ao criar suas próprias aplicações. O mesmo se aplica às URLs usadas. A URL new_note_spa para a qual as novas notas são enviadas, não segue as melhores práticas usadas atualmente.
Bibliotecas JavaScript
A aplicação de exemplo é feita com o chamado JavaScript "vanilla" (ou JavaScript "puro"), usando somente a API DOM e JavaScript para manipular a estrutura das páginas.
Em vez de usar somente JavaScript e a API DOM, é comum usar diferentes bibliotecas que contêm ferramentas mais fáceis de trabalhar em comparação com a API DOM para manipular páginas. Uma dessas bibliotecas é a popular jQuery.
A biblioteca jQuery foi desenvolvida quando as aplicações web seguiam principalmente o estilo tradicional do servidor gerando páginas HTML, cuja funcionalidade era aprimorada no lado do navegador usando JavaScript escrito com jQuery. Uma das razões para o sucesso de jQuery foi a sua compatibilidade cross-browser (compatibilidade entre navegadores). A biblioteca funcionava independentemente do navegador ou da empresa que a fez, então não havia necessidade de soluções específicas para cada navegador. Hoje em dia, usar jQuery não é tão justificável dada a evolução do JavaScript e dos navegadores mais populares, que de modo geral dão um bom suporte às funcionalidades básicas.
A ascensão das SPA trouxe várias formas mais "modernas" de desenvolvimento web do que jQuery. A favorita da primeira onda de desenvolvedores foi BackboneJS. Após o seu lançamento em 2012, AngularJS rapidamente se tornou quase o padrão de desenvolvimento web moderno da Google.
No entanto, a popularidade do Angular caiu em outubro de 2014 após a equipe do Angular anunciar que o suporte à versão 1 encerraria-se, e o Angular 2 não seria compatível com a primeira versão. Angular 2 e as versões mais recentes não foram muito bem recebidas.
Atualmente, a ferramenta mais popular para implementar a lógica do lado do cliente (navegador) de aplicações web é a biblioteca React do Facebook. Durante este curso, vamos nos familiarizar com o React e com a biblioteca Redux, que são frequentemente usadas juntas.
O status do React parece forte, mas o mundo de JavaScript está sempre mudando. Por exemplo, recentemente, um novato — VueJS — tem chamado a atenção.
Desenvolvimento Web Ful Stack
O que significa o nome do curso, Desenvolvimento Web Full Stack? A palavra "Full Stack" é um jargão de que todo mundo fala, mas ninguém sabe o que significa. Ou pelo menos, não há uma definição padrão para o termo.
Praticamente, todas as aplicações web têm, pelo menos, duas "camadas" (layers): o navegador, sendo mais próximo do usuário final (cliente), é a camada superior; enquanto que o servidor é a camada inferior. Há também, no geral, uma camada de banco de dados abaixo da do servidor. Podemos, portanto, pensar na arquitetura de uma aplicação web como uma espécie de pilha (stack) de camadas.
No geral, também falamos sobre o front-end e o back-end. O navegador é o front-end, e o JavaScript que roda no navegador é o código front-end. O servidor, por outro lado, é o back-end.
No contexto deste curso, desenvolvimento web full stack significa que nos concentramos em todas as partes da aplicação: front-end, back-end e banco de dados. Às vezes, o software no servidor e o sistema operacional dele são vistos como partes da pilha, mas não entraremos nesses detalhes.
Programaremos o back-end em JavaScript, usando o ambiente de execução Node.js. Usar a mesma linguagem de programação em múltiplas camadas da pilha dá ao desenvolvimento web Full Stack uma nova dimensão. No entanto, não é uma exigência do desenvolvimento web Full Stack usar a mesma linguagem de programação (JavaScript) para todas as camadas da pilha.
Era mais comum que os desenvolvedores se especializassem em uma dessas camadas, por exemplo, no back-end. As tecnologias no back-end e no front-end eram bastante diferentes. Com a tendência Full Stack, tornou-se comum que os desenvolvedores tenham a habilidade de programar em todas as camadas da aplicação e no banco de dados. Muitas vezes, os desenvolvedores full stack também precisam ter habilidades suficientes de configuração e administração para operar suas aplicações, como na nuvem, por exemplo.
Fadiga JavaScript
O desenvolvimento de aplicações web Full Stack é de muitas maneiras desafiador. Várias coisas estão acontecendo em vários lugares ao mesmo tempo, e a depuração (debug) é um pouco mais difícil se comparada com a depuração de softwares de desktop comuns. JavaScript nem sempre funciona da maneira que você espera que funcione (em comparação com muitas outras linguagens), e a forma assíncrona que seus ambientes de tempo de execução (runtime environments) funcionam cria todos os tipos de desafios. Comunicação na web exige conhecimento do protocolo HTTP. Também é preciso lidar com bancos de dados e administração e configuração de servidores. Também seria bom saber o suficiente de CSS para tornar as aplicações pelo menos apresentáveis.
O mundo JavaScript se desenvolve rápido, o que traz seus próprios desafios. Ferramentas, bibliotecas e a própria linguagem estão em constante desenvolvimento. Algumas pessoas começam a ficar cansadas das constantes mudanças e deram um nome para isso: fadiga JavaScript. Veja Como gerenciar a fadiga JavaScript no auth0 ou Fadiga JavaScript no site Medium.
Você sofrerá de fadiga JavaScript durante este curso. Felizmente para nós, existem algumas maneiras de suavizar a curva de aprendizado para que possamos começar com programação em vez de configuração. Não podemos evitar completamente a configuração, mas podemos avançar animadamente nas próximas semanas evitando as piores dores de cabeça da configuração.