b
Introduction aux applications Web
Avant de commencer la programmation, nous passerons en revue certains principes du développement Web en examinant un exemple d'application sur https://studies.cs.helsinki.fi/exampleapp.
L'application n'existe que pour introduire certains concepts de base du cours et n'est en aucun cas un exemple de comment une application Web moderne doit être créée. Au contraire, elle illustre certaines anciennes techniques du développement Web, qui pourraient même être considérées comme de mauvaises pratiques de nos jours.
Le code sera conforme aux bonnes pratiques actuelles à partir de la partie 1.
Ouvrez l'exemple d'application dans votre navigateur. Cela peut prendre un certain temps.
La 1ère règle du développement Web : gardez toujours la console de développement du navigateur ouverte sur votre navigateur Web. Sur macOS, ouvrez la console en appuyant simultanément sur F12 ou option-cmd-i. Sous Windows ou Linux, ouvrez la console en appuyant simultanément sur F12 ou ctrl-shift-i. La console peut également être ouverte via le menu contextuel.
N'oubliez pas de toujours garder la console ouverte quand vous développez des applications Web.
La console ressemble à ceci :
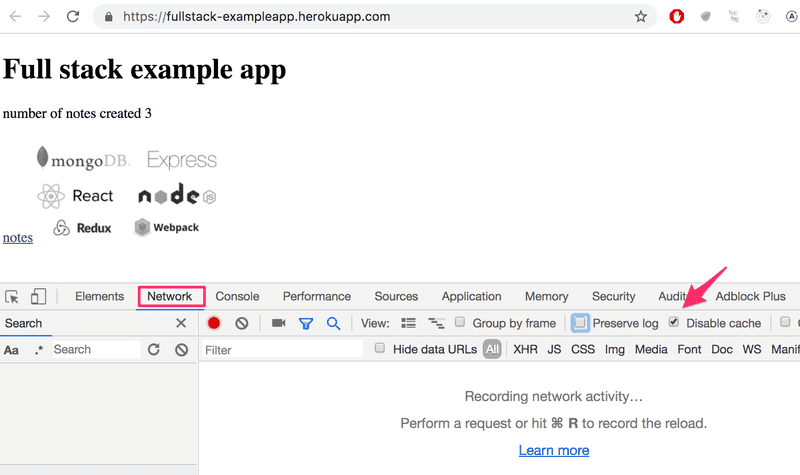
Assurez-vous que l'onglet Réseau est ouvert et cochez l'option Désactiver le cache comme indiqué. Conserver le journal peut également être utile (il enregistre les journaux imprimés par l'application lorsque la page est rechargée) ainsi que "Masquer les URL des extensions" (cache les requêtes issues d'extensions installées dans le navigateur, non visibles sur l'image ci-dessus)
NB : L'onglet le plus important est l'onglet Console. Cependant, dans cette introduction, nous utiliserons beaucoup l'onglet Réseau.
HTTP GET
Le serveur et le navigateur Web communiquent entre eux à l'aide du protocole HTTP. L'onglet Réseau montre comment le navigateur et le serveur communiquent.
Lorsque vous rechargez la page (appuyez sur les touches Fn-F5 sur PC, cmd-R sur macOS, ou cliquez sur le symbole ↻ de votre navigateur), la console indique que deux événements se sont produits :
- Le navigateur a récupéré le contenu de la page studies.cs.helsinki.fi/exampleapp du serveur
- Et a téléchargé l'image kuva.png
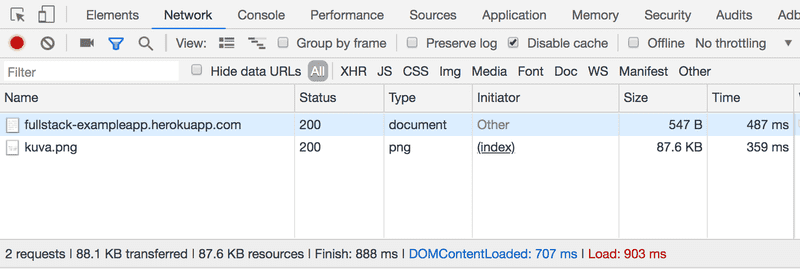
Sur un petit écran, vous devrez peut-être élargir la fenêtre de la console pour le voir.
Cliquer sur le premier événement révèle plus d'informations sur ce qui se passe :
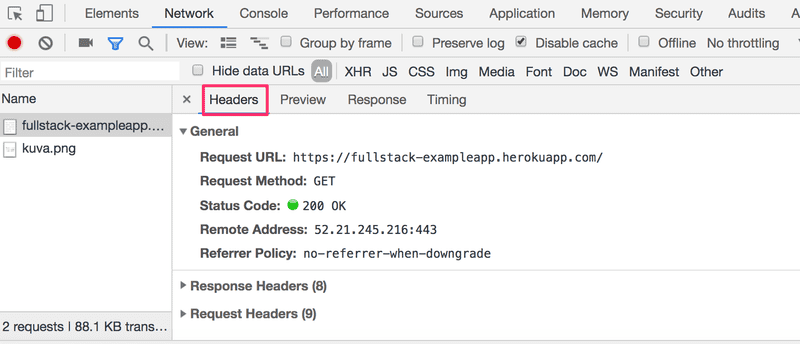
La partie supérieure, Général, montre que le navigateur a fait une requête à l'adresse https://studies.cs.helsinki.fi/exampleapp (bien que l'adresse ait légèrement changé depuis que cette photo a été prise) en utilisant la méthode GET, et que la requête a réussi, car la réponse du serveur avait le code de statut 200.
La requête et la réponse du serveur ont plusieurs en-têtes :
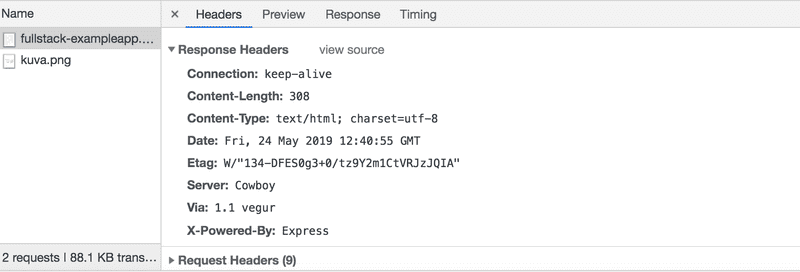
Les en-têtes de réponse en haut nous indiquent par ex. la taille de la réponse en octets et l'heure exacte de la réponse. Un en-tête important Content-Type nous indique que la réponse est un fichier texte codé en utf-8, dont le contenu a été formaté en HTML. De cette façon, le navigateur sait que la réponse est une page HTML normale et qu'il doit donc la restituer à l'écran "comme une page Web".
L'onglet Réponse affiche les données de réponse, une page HTML normale. La section body détermine la structure de la page rendue à l'écran :
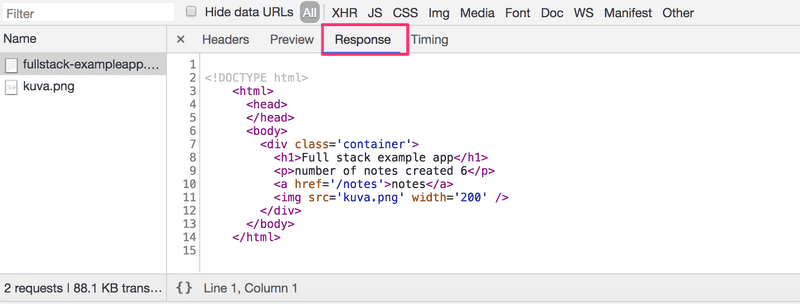
La page contient un élément div, qui à son tour contient un titre, un lien vers la page notes et une balise img et affiche le nombre de notes créées.
En raison de la balise img, le navigateur effectue une seconde requête HTTP pour récupérer l'image kuva.png du serveur. Les détails de la demande sont les suivants :
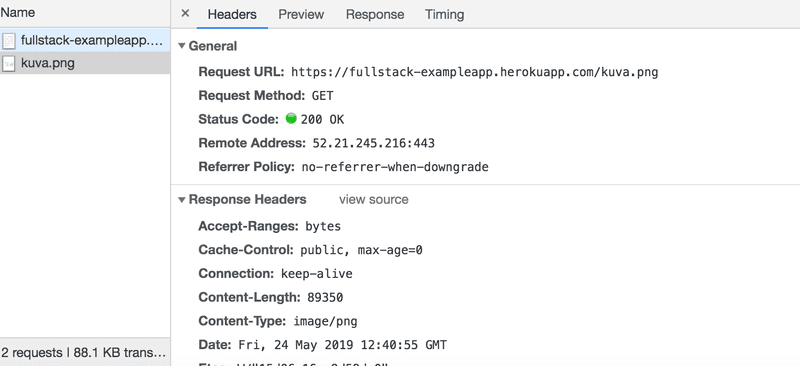
La requête a été faite à l'adresse https://studies.cs.helsinki.fi/exampleapp/kuva.png et son type est HTTP GET. Les en-têtes de réponse nous indiquent que la taille de la réponse est de 89350 octets et que son Content-type est image/png, c'est donc une image png. Le navigateur utilise ces informations pour restituer correctement l'image à l'écran.
{kind=link}
La chaîne d'événements provoquée par l'ouverture de la page https://studies.cs.helsinki.fi/exampleapp sur un navigateur se présente comme suit diagramme de séquence:

Tout d'abord, le navigateur envoie une requête HTTP GET au serveur pour récupérer le code HTML de la page. La balise img dans le code HTML invite le navigateur à récupérer l'image kuva.png. Le navigateur affiche la page HTML et l'image à l'écran.
Même s'il est difficile de s'en apercevoir, la page HTML commence à s'afficher avant que l'image n'ait été récupérée sur le serveur.
Applications Web traditionnelles
La page d'accueil de d'application d'exemple fonctionne comme une application Web traditionnelle. En entrant dans la page, le navigateur va chercher sur le serveur le document HTML détaillant la structure et le contenu textuel de la page.
Le serveur a formé ce document d'une manière ou d'une autre. Le document peut être un fichier texte statique enregistré dans le répertoire du serveur. Le serveur peut également former les documents HTML de manière dynamique selon le code de l'application, en utilisant par exemple les données d'une base de données. En l'occurence, le code HTML de l'application a été formé dynamiquement, car il contient des informations sur le nombre de notes créées.
Le code HTML de la page d'accueil est le suivant :
const getFrontPageHtml = (noteCount) => {
return(`
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<div class='container'>
<h1>Full stack example app</h1>
<p>number of notes created ${noteCount}</p>
<a href='/notes'>notes</a>
<img src='kuva.png' width='200' />
</div>
</body>
</html>
`)
}
app.get('/', (req, res) => {
const page = getFrontPageHtml(notes.length)
res.send(page)
})Vous n'avez pas besoin de comprendre ce code, pour le moment.
Le contenu de la page HTML a été enregistré en tant que "littéral de gabarit" (en anglais, "template string"), c'est à dire une chaîne de caractères qui permet d'évaluer, par exemple, des variables au milieu de celle-ci. La partie dynamique de la page d'accueil, le nombre de notes enregistrées (dans le code noteCount), est remplacée par le nombre actuel de notes (dans le code notes.length) dans le gabarit.
Écrire du HTML au milieu du code n'est bien sûr pas très malin, mais pour les programmeurs PHP de la vieille école, c'était une pratique normale.
Dans les applications Web traditionnelles, le navigateur est "stupide". Il récupère uniquement les données HTML du serveur et toute la logique d'application se trouve sur le serveur. Un serveur peut être créé en utilisant Java Spring (comme dans le cours de l'Université d'Helsinki Web-palvelinohjelmointi), Python Flask (comme dans le cours tietokantasovellus) ou avec Ruby on Rails pour ne citer que quelques exemples.
L'exemple utilise Express, sur Node.js. Ce cours utilisera Node.js et Express pour créer des serveurs Web.
Exécution de la logique d'application dans le navigateur
Gardez la Developer Console ouverte. Videz la console en cliquant sur le symbole 🚫 ou en tapant clear() dans la console. Désormais, lorsque vous accédez à la page notes, le navigateur effectue 4 requêtes HTTP :
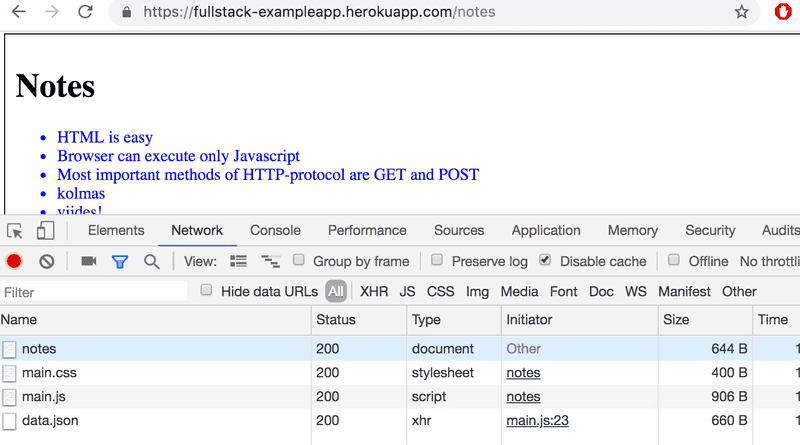
Toutes les demandes ont des types différents. Le type de la première requête est document. C'est le code HTML de la page, et il se présente comme suit :
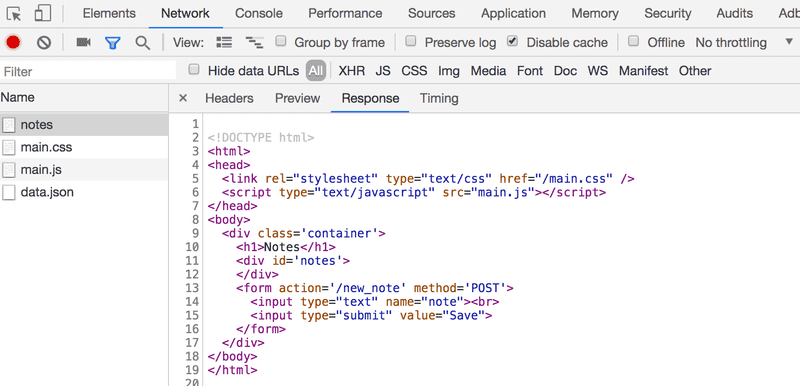
Lorsque l'on compare la page affichée sur le navigateur et le code HTML renvoyé par le serveur, on remarque que le code ne contient pas la liste des notes. La section head du code HTML contient un script-tag, qui amène le navigateur à récupérer un fichier JavaScript appelé main.js.
Le code JavaScript ressemble à ceci :
var xhttp = new XMLHttpRequest()
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
const data = JSON.parse(this.responseText)
console.log(data)
var ul = document.createElement('ul')
ul.setAttribute('class', 'notes')
data.forEach(function(note) {
var li = document.createElement('li')
ul.appendChild(li)
li.appendChild(document.createTextNode(note.content))
})
document.getElementById('notes').appendChild(ul)
}
}
xhttp.open('GET', '/data.json', true)
xhttp.send()Les détails du code ne sont pas importants pour le moment, mais du code a été inclus pour pimenter les images et le texte. Nous commencerons correctement à coder dans la partie 1. L'exemple de code de cette partie n'est en fait pas du tout pertinent pour les techniques de codage de ce cours.
Certains pourraient se demander pourquoi xhttp-object est utilisé à la place du fetch moderne. Cela est dû au fait de ne pas encore du tout vouloir entrer dans les promesses, et le code ayant un rôle secondaire dans cette partie. Nous reviendrons sur les moyens modernes de faire des requêtes au serveur dans la partie 2.
Immédiatement après avoir récupéré la balise script, le navigateur commence à exécuter le code.
Les deux dernières lignes indiquent au navigateur d'effectuer une requête HTTP GET à l'adresse du serveur /data.json :
xhttp.open('GET', '/data.json', true)
xhttp.send()Il s'agit de la dernière requête affichée dans l'onglet Réseau.
Nous pouvons essayer d'aller à l'adresse https://studies.cs.helsinki.fi/exampleapp/data.json directement depuis le navigateur :

On y retrouve les notes en JSON "raw data". Par défaut, les navigateurs basés sur Chromium ne sont pas très bons pour afficher les données JSON. Des plugins peuvent être utilisés pour gérer le formatage. Installez, par exemple, JSONVue sur Chrome, et rechargez la page. Les données sont maintenant bien formatées :
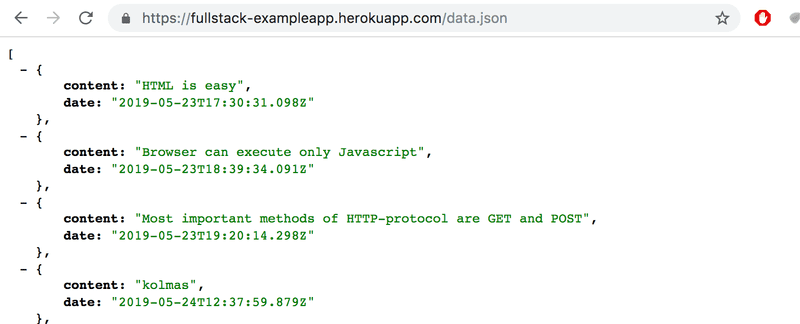
Ainsi, le code JavaScript de la page de notes ci-dessus télécharge les données JSON contenant les notes et forme une liste à puces à partir du contenu de la note :
Cela se fait grâce au code suivant :
const data = JSON.parse(this.responseText)
console.log(data)
var ul = document.createElement('ul')
ul.setAttribute('class', 'notes')
data.forEach(function(note) {
var li = document.createElement('li')
ul.appendChild(li)
li.appendChild(document.createTextNode(note.content))
})
document.getElementById('notes').appendChild(ul)Le code crée d'abord une liste non ordonnée avec une balise ul-tag...
var ul = document.createElement('ul')
ul.setAttribute('class', 'notes')... puis ajoute une balise li pour chaque note. Seul le champ content (contenu) de chaque note devient le contenu de la balise li. Les horodatages que l'on trouve dans les données brutes ne sont pas utilisés.
data.forEach(function(note) {
var li = document.createElement('li')
ul.appendChild(li)
li.appendChild(document.createTextNode(note.content))
})Ouvrez maintenant l'onglet Console des outils de développement :

En cliquant sur le petit triangle au début de la ligne, vous pouvez développer le texte sur la console.
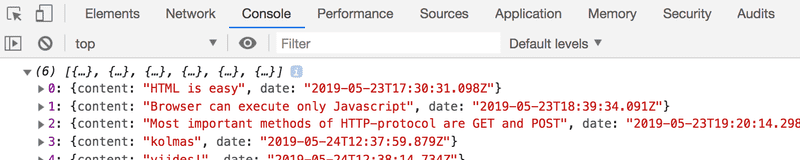
Cette sortie sur la console est causée par la commande console.log dans le code :
const data = JSON.parse(this.responseText)
console.log(data)Ainsi, après avoir reçu les données du serveur, le code les imprime sur la console.
L'onglet Console et la commande console.log vous deviendront très familiers pendant le cours.
Gestionnaires d'événements et fonctions de rappel (ou "callback")
La structure de ce code est un peu étrange :
var xhttp = new XMLHttpRequest()
xhttp.onreadystatechange = function() {
// code that takes care of the server response
}
xhttp.open('GET', '/data.json', true)
xhttp.send()La requête au serveur est envoyée sur la dernière ligne, mais le code pour gérer la réponse se trouve en fait plus haut. Que se passe-t-il?
xhttp.onreadystatechange = function () {Sur cette ligne, un gestionnaire d'événements pour l'événement onreadystatechange est défini pour l'objet xhttp effectuant la requête. Lorsque l'état de l'objet change, le navigateur appelle la fonction du gestionnaire d'événements. Le code de la fonction vérifie que readyState est égal à 4 (ce qui décrit la situation L'opération est terminée) et que le code d'état HTTP de la réponse est 200.
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
// code that takes care of the server response
}
}Ce mécanisme consistant à appeler des gestionnaires d'événements est très courant en JavaScript. Les fonctions de gestionnaire d'événements sont appelées fonctions callback. Le code d'application n'appelle pas lui-même les fonctions, mais l'environnement d'exécution - le navigateur - , appelle la fonction à un moment approprié, lorsque l'événement s'est produit.
Document Object Model ou DOM
Nous pouvons considérer les pages HTML comme des arborescences implicites.
html
head
link
script
body
div
h1
div
ul
li
li
li
form
input
inputLa même structure arborescente peut être vue sur l'onglet Éléments de la console.
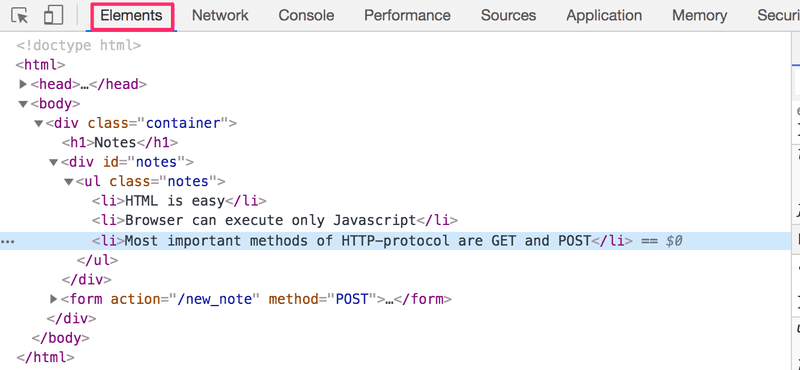
Le fonctionnement du navigateur est basé sur l'idée de représenter les éléments HTML sous forme d'arborescence.
Le Document Object Model, ou DOM, est une interface de programmation d'application (API) qui permet la modification par programmation des arborescences d'éléments correspondant aux pages Web.
Le code JavaScript introduit dans le chapitre précédent utilisait l'API DOM pour ajouter une liste de notes à la page.
Le code suivant crée un nouveau noeud pour la variable ul et y ajoute des noeuds enfants :
var ul = document.createElement('ul')
data.forEach(function(note) {
var li = document.createElement('li')
ul.appendChild(li)
li.appendChild(document.createTextNode(note.content))
})Enfin, la branche d'arborescence de la variable ul est connectée à sa place dans l'arborescence HTML de toute la page :
document.getElementById('notes').appendChild(ul)Manipulation du l'objet document depuis la console
Le noeud le plus haut de l'arborescence DOM d'un document HTML est appelé l'objet document. Nous pouvons effectuer diverses opérations sur une page Web à l'aide de l'API DOM. Vous pouvez accéder à l'objet document en tapant document dans l'onglet Console :
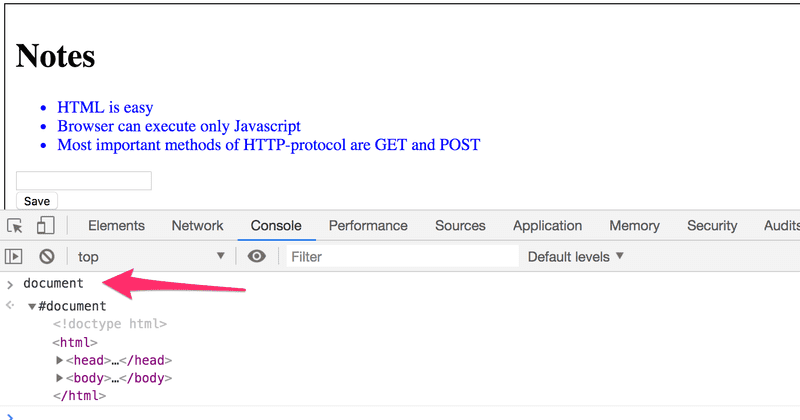
Ajoutons une nouvelle note à la page depuis la console.
Tout d'abord, nous allons obtenir la liste des notes de la page. La liste se trouve dans le premier élément ul de la page :
list = document.getElementsByTagName('ul')[0]Créez ensuite un nouvel élément li et ajoutez-y du contenu textuel :
newElement = document.createElement('li')
newElement.textContent = 'Page manipulation from console is easy'Et ajoutez le nouvel élément li à la liste :
list.appendChild(newElement)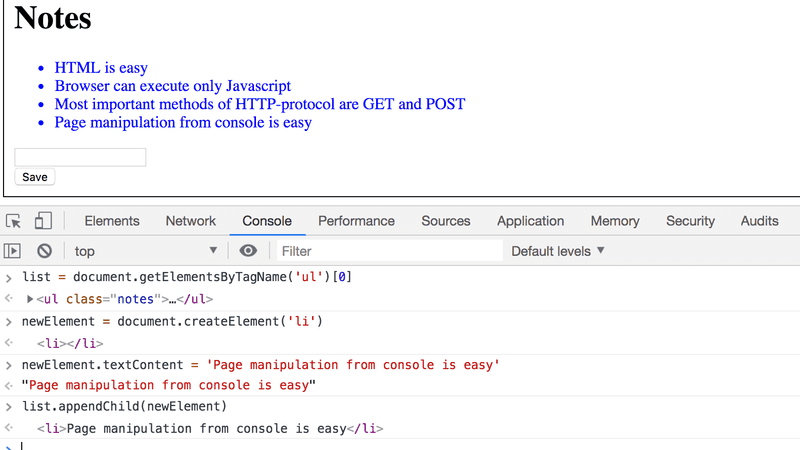
Même si la page est mise à jour sur votre navigateur, les modifications ne sont pas permanentes. Si la page est rechargée, la nouvelle note disparaîtra, car les modifications n'ont pas été transmises au serveur. Le code JavaScript que le navigateur récupère créera toujours la liste des notes basées sur les données JSON à partir de l'adresse https://studies.cs.helsinki.fi/exampleapp/data.json.
CSS
L'élément head du code HTML de la page Notes contient une balise link, qui détermine que le navigateur doit récupérer une feuille de style CSS à partir de l'adresse main.css.
Les feuilles de style en cascade, ou CSS, sont un langage de feuille de style utilisé pour déterminer l'apparence des pages Web.
Le fichier CSS récupéré ressemble à ceci :
.container {
padding: 10px;
border: 1px solid;
}
.notes {
color: blue;
}Le fichier définit deux sélecteurs de classe. Ceux-ci sont utilisés pour sélectionner certaines parties de la page et pour définir des règles de style pour les mettre en forme.
Une définition de sélecteur de classe commence toujours par un point et contient le nom de la classe.
Les classes sont des attributs, qui peuvent être ajoutés aux éléments HTML.
Les attributs CSS peuvent être examinés dans l'onglet éléments de la console :
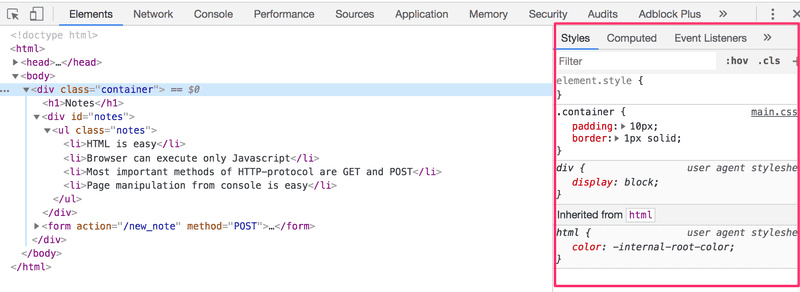
L'élément div le plus externe possède la classe container. L'élément ul contenant la liste des notes possède la classe notes.
La règle CSS définit que les éléments avec la classe container seront délimités par une bordure large d'un pixel. Il définit également 10 pixels de padding sur l'élément. Cela ajoute un espace vide entre le contenu de l'élément et la bordure.
La deuxième règle CSS définit la couleur du texte des notes en bleu.
Les éléments HTML peuvent également avoir d'autres attributs en dehors des classes. L'élément div contenant les notes a un attribut id. Le code JavaScript utilise l'identifiant pour trouver l'élément.
L'onglet Éléments de la console peut être utilisé pour changer les styles des éléments.
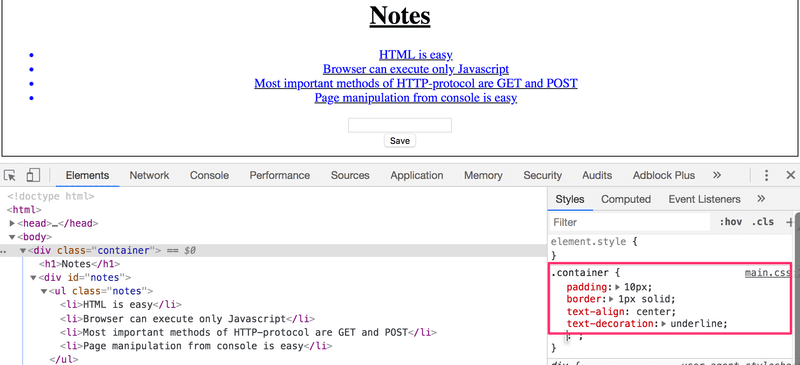
Les modifications apportées sur la console ne seront pas permanentes. Si vous souhaitez apporter des modifications durables, elles doivent être enregistrées dans la feuille de style CSS sur le serveur.
Chargement d'une page contenant JavaScript - révision
Passons en revue ce qui se passe lorsque la page https://studies.cs.helsinki.fi/exampleapp/notes est ouverte sur le navigateur.
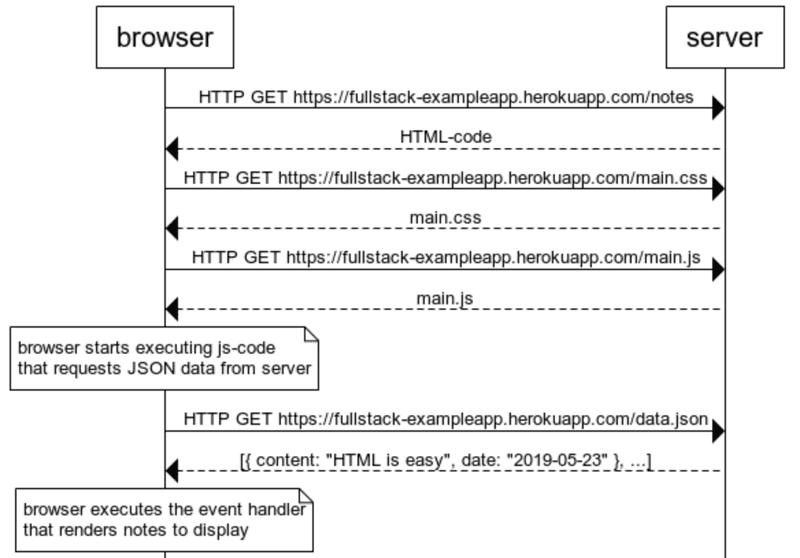
- Le navigateur va chercher le code HTML définissant le contenu et la structure de la page sur le serveur à l'aide d'une requête HTTP GET.
- Les liens dans le code HTML amènent le navigateur à récupérer également la feuille de style CSS main.css...
- ...et un fichier de code JavaScript main.js
- Le navigateur exécute le code JavaScript. Le code fait une requête HTTP GET à l'adresse https://studies.cs.helsinki.fi/exampleapp/data.json, qui renvoie les notes sous forme de données JSON.
- Lorsque les données ont été récupérées, le navigateur exécute un gestionnaire d'événements, qui affiche les notes sur la page à l'aide de l'API DOM.
Formulaires et HTTP POST
Examinons maintenant comment l'ajout d'une nouvelle note est effectué.
La page Notes contient un formulaire défini par un élément .
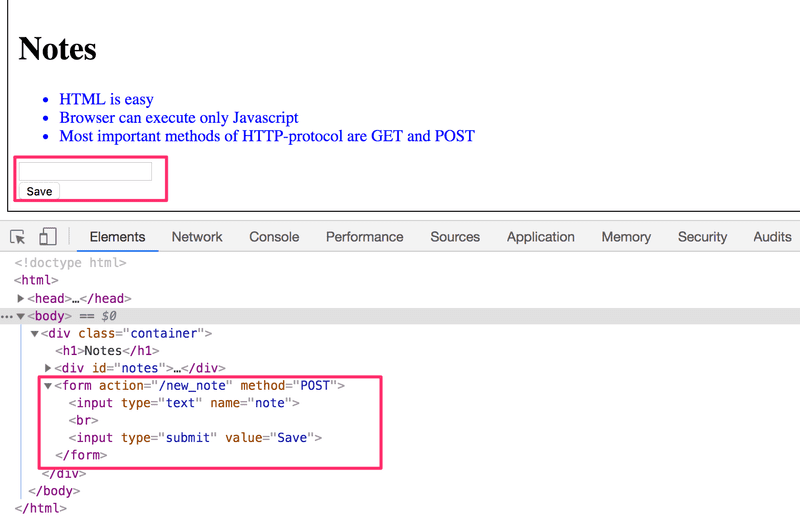
Lorsque le bouton du formulaire est cliqué, le navigateur enverra l'entrée de l'utilisateur au serveur. Ouvrons l'onglet Réseau et voyons à quoi ressemble l'envoi du formulaire :
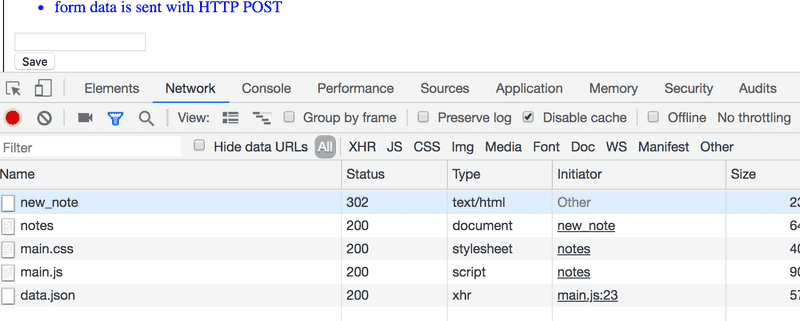
Étonnamment, la soumission du formulaire déclenche pas moins de cinq requêtes HTTP. Le premier est l'événement de soumission de formulaire. Zoomons dessus :
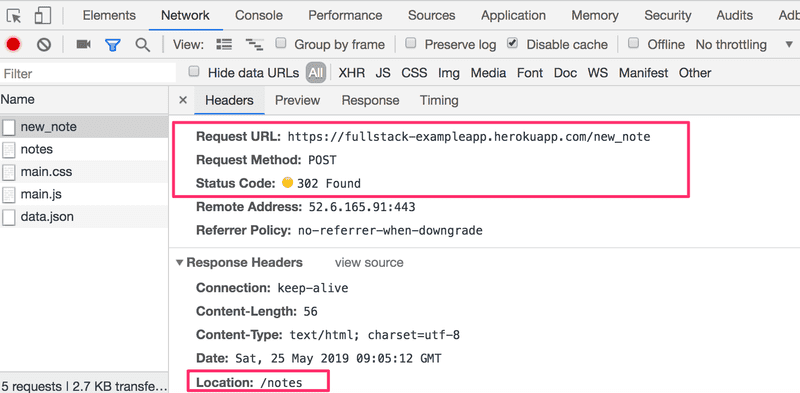
Il s'agit d'une requête HTTP POST à l'adresse du serveur new_note. Le serveur répond avec le code d'état HTTP 302. Il s'agit d'une redirection d'URL, par laquelle le serveur demande au navigateur de faire une nouvelle requête HTTP GET à l'adresse définie dans l'en-tête de requête Location - c'est-à-dire l'adresse notes.
Ainsi, le navigateur recharge la page Notes. Le rechargement provoque trois requêtes HTTP supplémentaires : la récupération de la feuille de style (main.css), du code JavaScript (main.js) et des données brutes des notes (data.json).
L'onglet réseau affiche également les données soumises avec le formulaire :
NB: Dans les dernières versions de Chrome, les informations sur les données de formulaire se trouvent dans le nouvel onglet "Charge utile" (ou "Payload"), situé à droite de l'onglet En-têtes
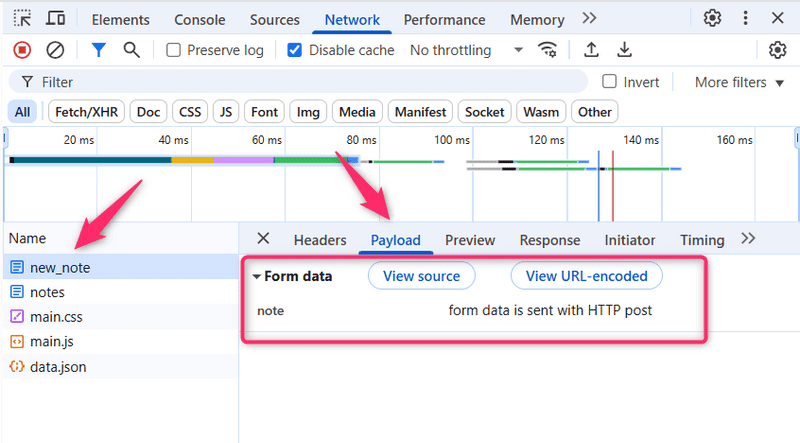
La balise Form a les attributs action et method, qui définissent que la soumission du formulaire se fait sous la forme d'une requête HTTP POST à l'adresse new_note.
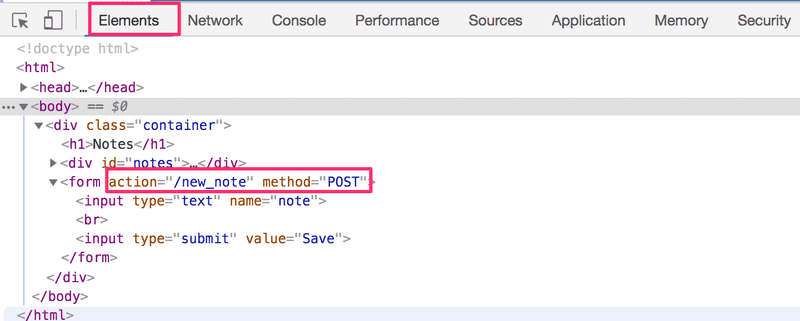
Le code sur le serveur responsable de la requête POST est assez simple (NB : ce code est sur le serveur, et non sur le code JavaScript récupéré par le navigateur) :
app.post('/new_note', (req, res) => {
notes.push({
content: req.body.note,
date: new Date(),
})
return res.redirect('/notes')
})Les données sont envoyées dans le corps de la requête POST.
Le serveur peut accéder aux données en accédant au champ req.body de l'objet de requête req.
Le serveur crée un nouvel objet note et l'ajoute à un tableau appelé notes.
notes.push({
content: req.body.note,
date: new Date(),
})Les objets Note ont deux champs : content contenant le contenu proprement dit de la note et date contenant la date et l'heure de création de la note.
Le serveur n'enregistre pas les nouvelles notes dans une base de données, de sorte que les nouvelles notes disparaissent lorsque le serveur est redémarré.
AJAX
La page Notes de l'application suit un style de développement Web du début des années 90 et utilise "Ajax". Cela fait qu'il est représentatif des sites du début des années 2000 utilisant des technologies web alors au sommet de leur popularité.
AJAX (JavaScript et XML asynchrones) est un terme introduit en février 2005 suite aux progrès de la technologie des navigateurs pour décrire une nouvelle approche révolutionnaire qui permettait de récupérer du contenu sur des pages Web à l'aide de JavaScript inclus dans le code HTML, sans qu'il soit nécessaire de recharger l'affichage de l'ensemble de la page.
Avant l'ère AJAX, toutes les pages Web fonctionnaient comme les applications Web traditionnelles que nous avons vues précédemment dans ce chapitre. Toutes les données affichées sur la page étaient issues du code HTML généré par le serveur.
La page Notes utilise AJAX pour récupérer les données des notes. La soumission du formulaire utilise toujours le mécanisme traditionnel de soumission de formulaires Web.
Les URL de notre exemple d'application reflètent les pratiques d'un temps ancien et insouciant. Les données JSON sont extraites de l'URL https://studies.cs.helsinki.fi/exampleapp/data.json et les nouvelles notes sont envoyées à l'URL https://studies.cs.helsinki.fi/exampleapp/new_note. De nos jours, de telles URL ne seraient pas considérées comme acceptables, car elles ne respectent pas les conventions généralement reconnues des API REST, que nous étudierons plus en détail dans la partie 3
L'approche appelée AJAX est maintenant si banale qu'elle est tenue pour acquise. Le terme est tombé dans l'oubli, et la nouvelle génération n'en a même pas entendu parler.
Application à page unique
Dans notre exemple d'application, la page d'accueil fonctionne comme une page Web traditionnelle : toute la logique se trouve sur le serveur et le navigateur affiche uniquement le code HTML conformément aux instructions.
La page Notes délègue au navigateur une partie de la responsabilité de générer le code HTML pour les notes existantes. Le navigateur remplit cette tâche en exécutant le code JavaScript qu'il a récupéré sur le serveur. Le code récupère les notes sur le serveur sous forme de données JSON et ajoute des éléments HTML pour afficher les notes sur la page à l'aide de DOM-API.
Ces dernières années, le style application web monopage en anglais SPA (single page application) de création d'applications Web a émergé. Les sites Web de style SPA ne récupèrent pas différentes pages sur le serveur comme le fait notre exemple d'application, mais ne sont constituées que d'une seule page HTML extraite du serveur, dont le contenu est manipulé avec du code JavaScript qui s'exécute dans le navigateur.
La page Notes de notre application ressemble un peu aux applications de style SPA, mais n'en est pas tout à fait une. Même si la logique de rendu des notes est exécutée sur le navigateur, la page utilise toujours la méthode traditionnelle d'ajout de nouvelles notes. Les données sont envoyées au serveur avec la soumission du formulaire, et le serveur demande au navigateur de recharger la page Notes avec une redirection.
Une version SPA de notre exemple d'application peut être trouvée sur https://studies.cs.helsinki.fi/exampleapp/spa. À première vue, l'application ressemble exactement à la précédente. Le code HTML est presque identique, mais le fichier JavaScript est différent (spa.js) et il y a un petit changement dans la façon dont la balise
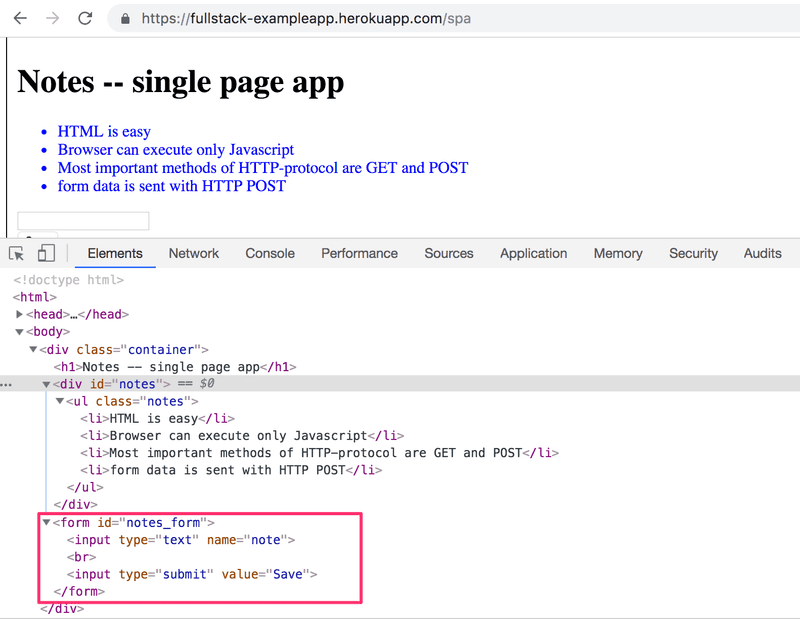
Le formulaire n'a pas d'attributs action ou method pour définir comment et où envoyer les données d'entrée.
Ouvrez l'onglet Réseau et videz-le. Lorsque vous créez maintenant une nouvelle note, vous remarquerez que le navigateur n'envoie qu'une seule requête au serveur.
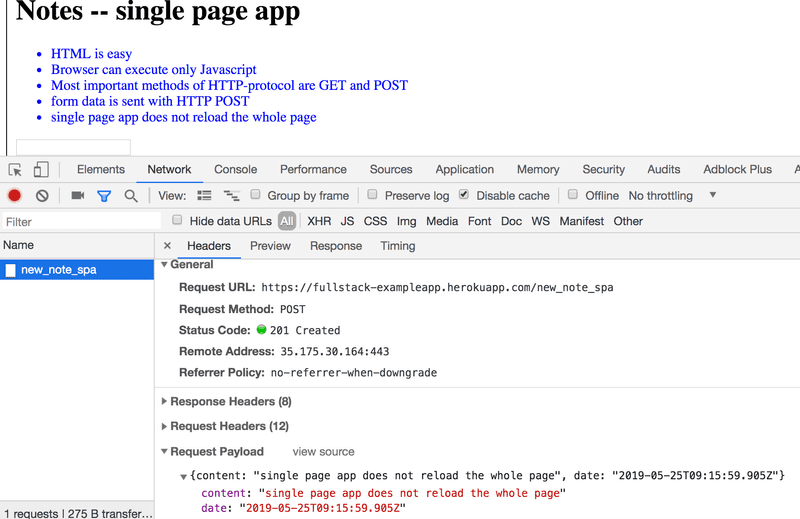
La requête POST à l'adresse new_note_spa contient la nouvelle note sous forme de données JSON contenant à la fois le contenu de la note (content) et l'horodatage ( date) :
{
content: "single page app does not reload the whole page",
date: "2019-05-25T15:15:59.905Z"
}L'en-tête Content-Type de la requête indique au serveur que les données incluses sont représentées au format JSON.
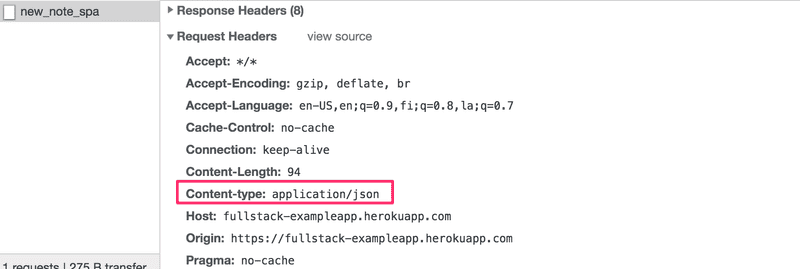
Sans cet en-tête, le serveur ne saurait pas lire correctement les données.
Le serveur répond avec le code d'état 201 créé. Cette fois, le serveur ne demande pas de redirection, le navigateur reste sur la même page et n'envoie pas d'autres requêtes HTTP.
La version SPA de l'application n'envoie pas les données de formulaire de manière traditionnelle, mais utilise à la place le code JavaScript qu'elle a récupéré sur le serveur. Nous allons étudier un peu ce code, même si en comprendre tous les détails n'est pas encore important.
var form = document.getElementById('notes_form')
form.onsubmit = function(e) {
e.preventDefault()
var note = {
content: e.target.elements[0].value,
date: new Date(),
}
notes.push(note)
e.target.elements[0].value = ''
redrawNotes()
sendToServer(note)
}La commande document.getElementById('notes_form') indique au code de récupérer l'élément de formulaire de la page et d'enregistrer un gestionnaire d'événements pour gérer l'évènement de soumission du formulaire. Le gestionnaire d'événements appelle immédiatement la méthode e.preventDefault() pour empêcher le comportement par défaut de la soumission de formulaire. La méthode par défaut enverrait les données au serveur et provoquerait une nouvelle requête GET, ce que nous ne voulons pas.
Ensuite, le gestionnaire d'événements crée une nouvelle note, l'ajoute à la liste des notes avec la commande notes.push(note), rafraîchit la liste des notes sur la page et envoie la nouvelle note au serveur.
Le code qui permet d'envoyer la note au serveur est le suivant :
var sendToServer = function(note) {
var xhttpForPost = new XMLHttpRequest()
// ...
xhttpForPost.open('POST', '/new_note_spa', true)
xhttpForPost.setRequestHeader(
'Content-type', 'application/json'
)
xhttpForPost.send(JSON.stringify(note))
}Le code détermine que les données doivent être envoyées avec une requête HTTP POST et que le type de données doit être JSON. Le type de données est déterminé avec un en-tête Content-type. Ensuite, les données sont envoyées sous forme de chaîne JSON.
Le code d'application est disponible sur https://github.com/mluukkai/example_app. Il convient de rappeler que l'application est uniquement destinée à démontrer les concepts du cours. Son code suit un style de développement médiocre par bien des aspects et ne doit pas être utilisé comme exemple lors de la création de vos propres applications. Il en va de même pour les URL utilisées. L'URL new_note_spa, à laquelle les nouvelles notes sont envoyées, ne respecte pas les meilleures pratiques actuelles.
Bibliothèques JavaScript
L'exemple d'application est réalisé avec ce qu'on appelle vanilla JavaScript, en utilisant uniquement l'API DOM et des fonctions standard de JavaScript pour manipuler la structure des pages.
Au lieu d'utiliser uniquement JavaScript et l'API DOM, différentes bibliothèques contenant des outils plus faciles à utiliser que l'API DOM sont souvent utilisées pour manipuler les pages. L'une de ces bibliothèques est la très populaire jQuery.
jQuery a été développé à l'époque où les applications Web suivaient principalement le style traditionnel du serveur générant des pages HTML, dont la fonctionnalité était améliorée du côté du navigateur à l'aide de JavaScript écrit avec jQuery. L'une des raisons du succès de jQuery était sa compatibilité revendiquée entre navigateurs. La bibliothèque fonctionnait quel que soit le navigateur ou la société qui l'avait créée, il n'y avait donc pas besoin de solutions spécifiques par navigateur. De nos jours, l'utilisation de jQuery n'est plus aussi justifiée compte tenu de l'avancement de JavaScript, et les navigateurs les plus populaires supportent généralement bien les fonctionnalités de base.
L'essor des applications à page unique a engendré des méthodes de développement Web plus "modernes" que jQuery. Le favori d'une première vague de développeurs était BackboneJS. Après son lancement en 2012, Google AngularJS est rapidement devenu une quasi norme de facto du développement Web moderne.
Cependant, la popularité d'Angular a chuté en octobre 2014 après que l'équipe d'Angular a annoncé que le support de la version 1 prendrait fin, et qu'Angular 2 ne serait pas rétrocompatible avec la première version. Angular 2 et les versions plus récentes n'ont pas été accueillies très chaleureusement.
Actuellement, l'outil le plus populaire pour implémenter la logique côté navigateur des applications Web est la bibliothèque React de Facebook. Au cours de ce cours, nous nous familiariserons avec React et la bibliothèque Redux, qui sont fréquemment utilisées ensemble.
La position de React semble aujourd'hui dominante, mais le monde de JavaScript est en constante évolution. Par exemple, récemment, un nouveau venu - VueJS - a suscité un intérêt certain.
Développement Web Full Stack
Que signifie le nom du cours, Développement Web Full Stack ? Le full stack est un mot à la mode dont tout le monde parle, alors que personne ne sait vraiment ce que cela signifie. Ou du moins, il n'y a pas de définition convenue pour le terme.
Preque toutes les applications Web ont (au moins) deux "couches": le navigateur, étant plus proche de l'utilisateur final, est la couche supérieure et le serveur contitue la couche inférieure. Il y a souvent aussi une couche de base de données sous le serveur. On peut donc penser à l'architecture d'une application web comme une sorte de pile (stack) de couches.
Souvent, on parle aussi du frontend et du backend. Le navigateur est le frontend, la partie client, et le code JavaScript qui s'exécute sur le navigateur est le code de la partie client. Le serveur, quant à lui, est le backend.
Dans le cadre de ce cours, le développement web full stack signifie que nous nous concentrons sur toutes les parties de l'application : le frontend, le backend et la base de données. Parfois, le logiciel sur le serveur et son système d'exploitation sont considérés comme une partie distincte de l'application, mais nous ne les aborderons pas dans ici.
Nous allons coder le backend avec JavaScript, en utilisant l'environnement d'exécution Node.js. L'utilisation du même langage de programmation pour le backend et le frontend confère au développement d'une application web complète une toute nouvelle dimension. Cependant, il n'est pas obligatoire pour le développement Web "full-stack" d'utiliser le même langage de programmation (JavaScript) pour toutes les parties de l'application.
Auparavant, il était plus courant pour les développeurs de se spécialiser dans une de ses parties, par exemple le backend. Les technologies sur le backend et le frontend étaient assez différentes. Avec la tendance Full stack, il est devenu courant pour les développeurs de maîtriser toutes les couches de l'application et de la base de données. Souvent, les développeurs full stack doivent également avoir suffisamment de compétences en configuration et en administration pour faire fonctionner leur application, par exemple dans le cloud.
Fatigue JavaScript
Le développement Web est difficile à bien des égards. Les choses se passent dans plusieurs endroits à la fois, et le débogage est un peu plus difficile qu'avec les applications de bureau classiques. JavaScript ne fonctionne pas toujours comme prévu (par rapport à de nombreux autres langages), et le fonctionnement asynchrone de ses environnements d'exécution entraîne toutes sortes de défis. Communiquer sur le web nécessite la connaissance du protocole HTTP. Il faut également gérer les bases de données et l'administration et la configuration des serveurs. Il serait également bon de connaître suffisamment de CSS pour rendre les applications au moins quelque peu présentables.
Le monde de JavaScript se développe rapidement, ce qui apporte son lot de défis. Les outils, les bibliothèques et le langage lui-même sont en constante évolution. Certains commencent à en avoir assez du changement constant et ont inventé un terme pour cela : fatigue JavaScript. Voir How to Manage JavaScript Fatigue on auth0 ou JavaScript fatigue on Medium.
Vous souffrirez vous-même de JavaScript fatigue pendant ce cours. Heureusement pour nous, il existe plusieurs façons de lisser la courbe d'apprentissage, et nous pouvons commencer par le codage au lieu de la configuration. Nous ne pouvons pas complètement éviter la configuration, mais nous pouvons joyeusement aller de l'avant dans les prochaines semaines tout en évitant pourl'instant l'exploration des enfers de la configuration.