c
Stocker des données sur MongoDB
Avant de passer au sujet principal de la persistance des données dans une base de données, nous allons jeter un coup d'oeil à quelques façons différentes de déboguer les applications Node.
Débogage des applications Node
Le débogage des applications Node est légèrement plus difficile que le débogage du JavaScript exécuté dans votre navigateur. L'impression à la console est une méthode éprouvée et vraie, et cela vaut toujours la peine de la faire. Il y a des gens qui pensent que des méthodes plus sophistiquées devraient être utilisées à la place, mais je ne suis pas d'accord. Même l'élite mondiale des développeurs open source utilise cette méthode.
Visual Studio Code
Le débogueur de Visual Studio Code peut être utile dans certaines situations. Vous pouvez lancer l'application en mode débogage comme ceci :
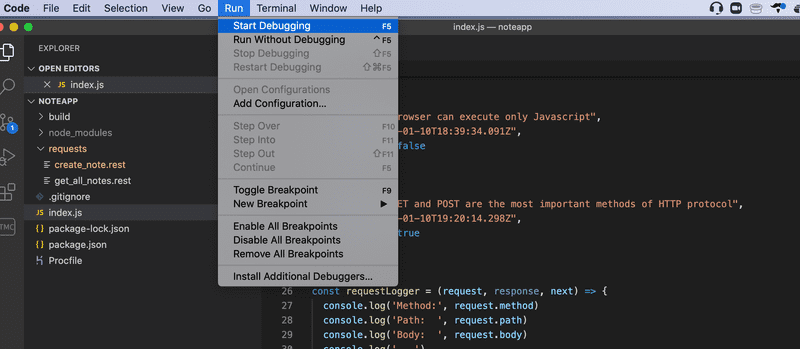
Notez que l'application ne doit pas être exécutée dans une autre console, sinon le port sera déjà utilisé.
NB Une version plus récente de Visual Studio Code peut avoir Run au lieu de Debug. De plus, vous devrez peut-être configurer votre fichier launch.json pour lancer le débogage. Cela peut être fait en choisissant Add Configuration... _ dans le menu déroulant, qui se trouve à côté du bouton vert de lecture et au-dessus du menu _VARIABLES, et sélectionnez Run "npm start" dans un terminal de débogage. Pour des instructions de configuration plus détaillées, consultez la [documentation sur le débogage] de Visual Studio Code (https://code.visualstudio.com/docs/editor/debugging).
Vous pouvez voir ci-dessous une capture d'écran où l'exécution du code a été interrompue au milieu de l'enregistrement d'une nouvelle note :
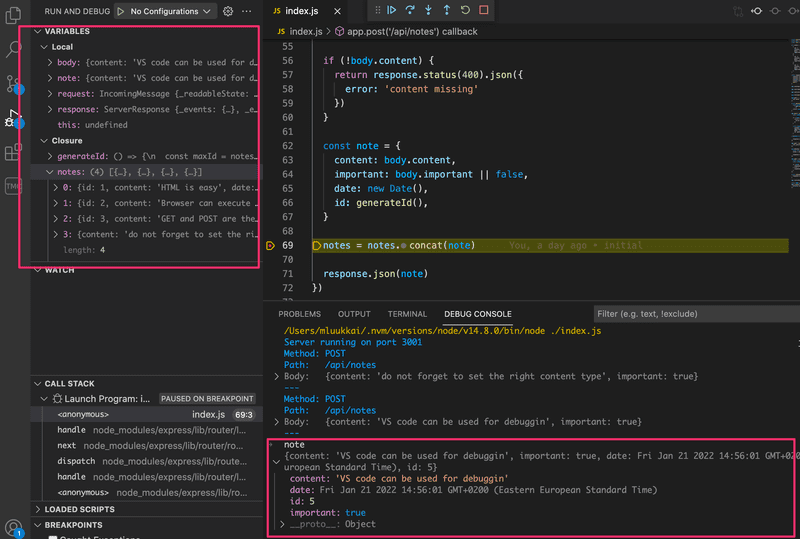
L'exécution s'est arrêtée au point d'arrêt à la ligne 63. Dans la console, vous pouvez voir la valeur de la variable note. Dans la fenêtre en haut à gauche, vous pouvez voir d'autres choses liées à l'état de l'application.
Les flèches en haut peuvent être utilisées pour contrôler le flux du débogueur.
Pour une raison quelconque, je n'utilise pas beaucoup le débogueur de Visual Studio Code.
Outils de développement de Chrome
Le débogage est également possible avec la console de développement de Chrome en démarrant votre application avec la commande :
node --inspect index.jsVous pouvez accéder au débogueur en cliquant sur l'icône verte - le logo de node - qui apparaît dans la console du développeur de Chrome :

La vue de débogage fonctionne de la même manière que pour les applications React. L'onglet Sources peut être utilisé pour définir des points d'arrêt où l'exécution du code sera mise en pause.
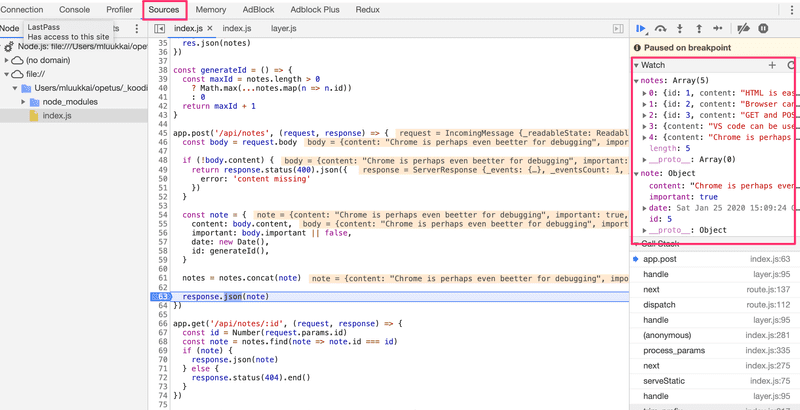
Tous les messages console.log de l'application apparaîtront dans l'onglet Console du débogueur. Vous pouvez également inspecter les valeurs des variables et exécuter votre propre code JavaScript.
Questionnez tout
Le débogage des applications Full Stack peut sembler délicat au début. Bientôt, notre application aura également une base de données en plus du frontend et du backend, et il y aura de nombreuses zones potentielles de bugs dans l'application.
Lorsque l'application "ne fonctionne pas", nous devons d'abord déterminer où le problème se situe réellement. Il est très fréquent que le problème se trouve à un endroit où vous ne vous y attendiez pas, et il peut se passer des minutes, des heures, voire des jours avant que vous ne trouviez la source du problème.
La clé est d'être systématique. Puisque le problème peut exister n'importe où, vous devez tout remettre en question, et éliminer toutes les possibilités une par une. La journalisation sur la console, Postman, les débogueurs et l'expérience vous aideront.
Lorsque des bugs surviennent, la pire des stratégies possibles est de continuer à écrire du code. Cela garantira que votre code aura bientôt encore plus de bugs, et que leur débogage sera encore plus difficile. Le principe stop and fix du Toyota Production Systems est également très efficace dans cette situation.
MongoDB
Afin de stocker indéfiniment nos notes enregistrées, nous avons besoin d'une base de données. La plupart des cours dispensés à l'Université d'Helsinki utilisent des bases de données relationnelles. Dans la majeure partie de ce cours, nous utiliserons MongoDB qui est une base de données documentaire (https://en.wikipedia.org/wiki/Document-oriented_database).
La raison de l'utilisation de Mongo comme base de données est sa moindre complexité par rapport à une base de données relationnelle. La partie 13 du cours montre comment construire des backends node.js qui utilisent une base de données relationnelle.
Les bases de données documentaires diffèrent des bases de données relationnelles par la manière dont elles organisent les données ainsi que par les langages d'interrogation qu'elles prennent en charge. Les bases de données documentaires sont généralement classées sous le terme générique NoSQL.
Pour en savoir plus sur les bases de données documentaires et les bases de données NoSQL, consultez le support de cours de la semaine 7 du cours Introduction aux bases de données. Malheureusement, ce matériel n'est actuellement disponible qu'en finnois.
Lisez maintenant les chapitres sur les collections et les documents du manuel MongoDB pour avoir une idée de base sur la façon dont une base de données de documents stocke les données.
Naturellement, vous pouvez installer et exécuter MongoDB sur votre propre ordinateur. Cependant, l'Internet regorge également de services de base de données Mongo que vous pouvez utiliser. Notre fournisseur MongoDB préféré dans ce cours sera MongoDB Atlas.
Une fois que vous avez créé et connecté votre compte, commençons par sélectionner l'option gratuite :
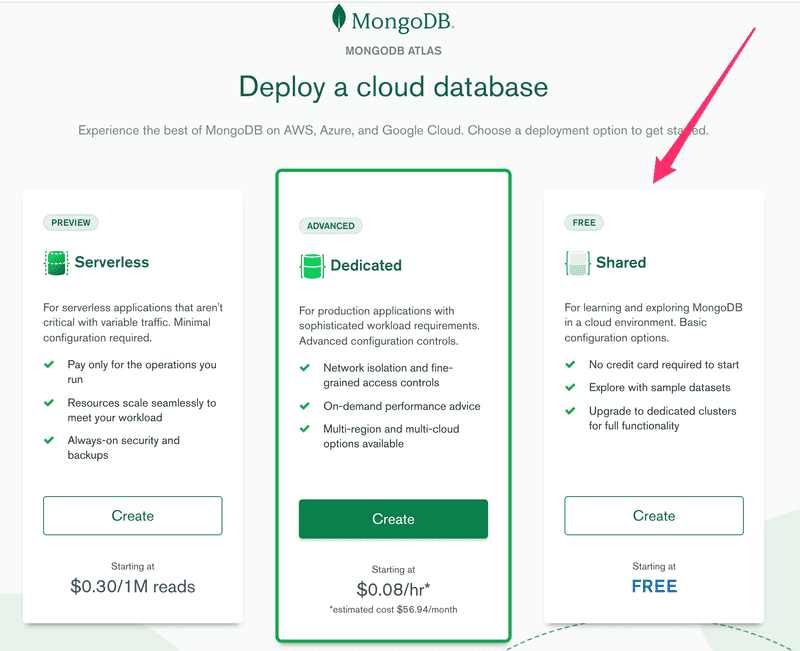
Choisissez le fournisseur de cloud et l'emplacement et créez le cluster :
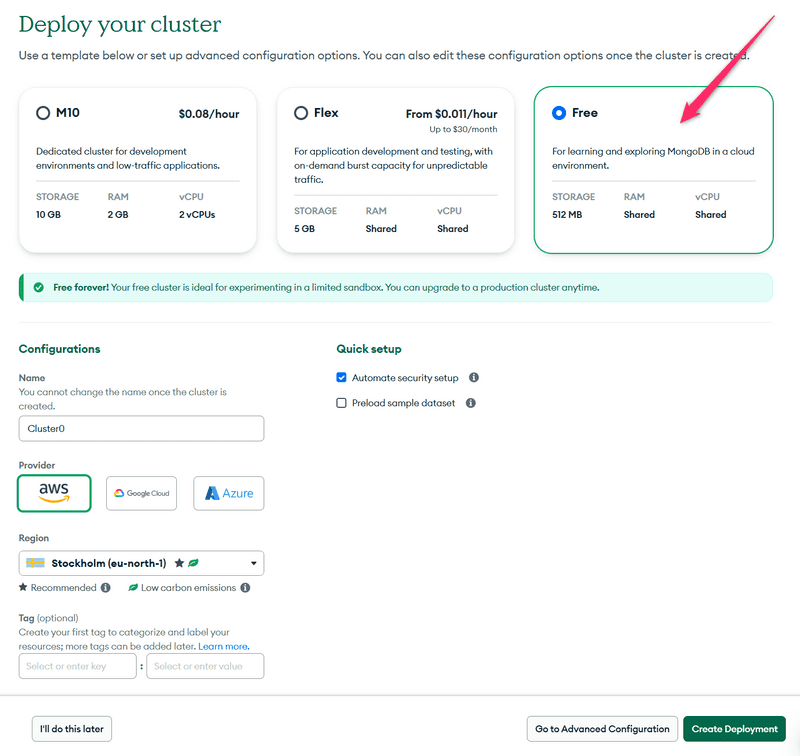
Attendons que le cluster soit prêt à être utilisé. Cela peut prendre quelques minutes.
NB ne continuez pas avant que le cluster soit prêt.
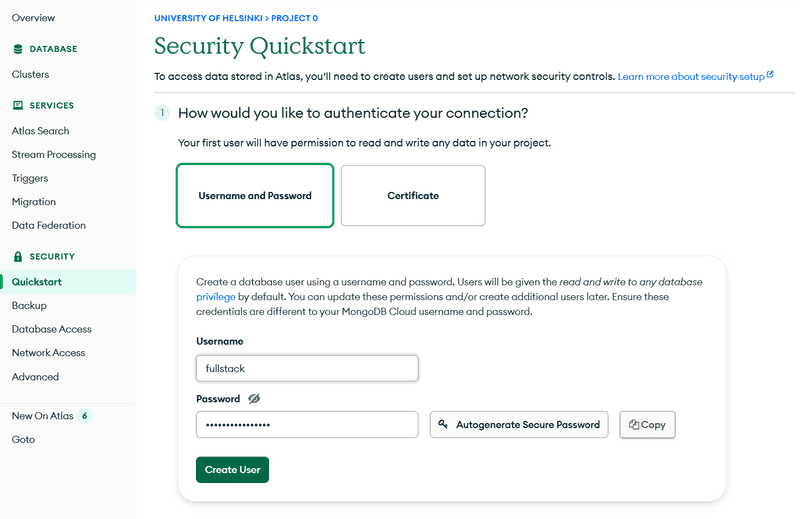
Utilisons l'onglet security pour créer les informations d'identification des utilisateurs pour la base de données. Veuillez noter que ce ne sont pas les mêmes informations d'identification que vous utilisez pour vous connecter à MongoDB Atlas. Ils seront utilisés par votre application pour se connecter à la base de données.
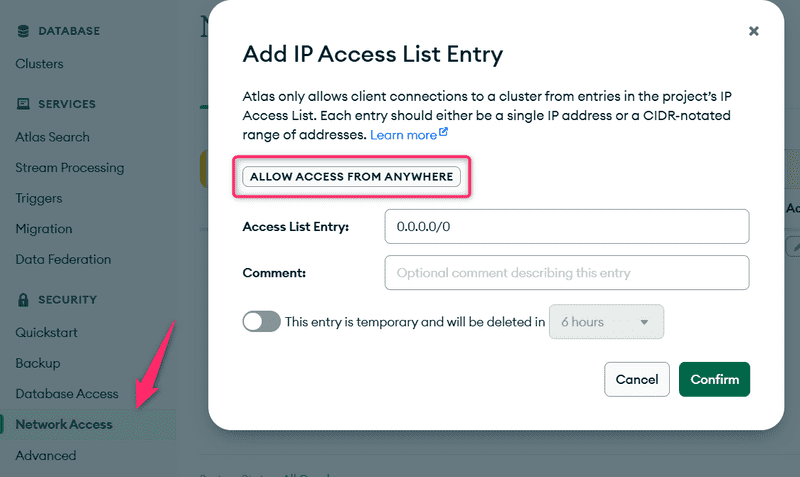
Ensuite, nous devons définir les adresses IP qui sont autorisées à accéder à la base de données. Pour des raisons de simplicité, nous allons autoriser l'accès à partir de toutes les adresses IP :
Enfin, nous sommes prêts à nous connecter à notre base de données. Commencez par cliquer sur connect :
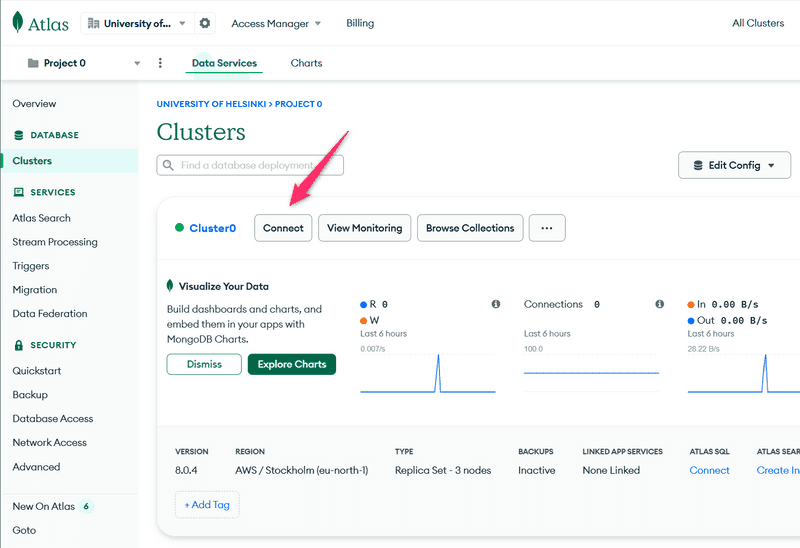
et choisissez Connecter votre application :
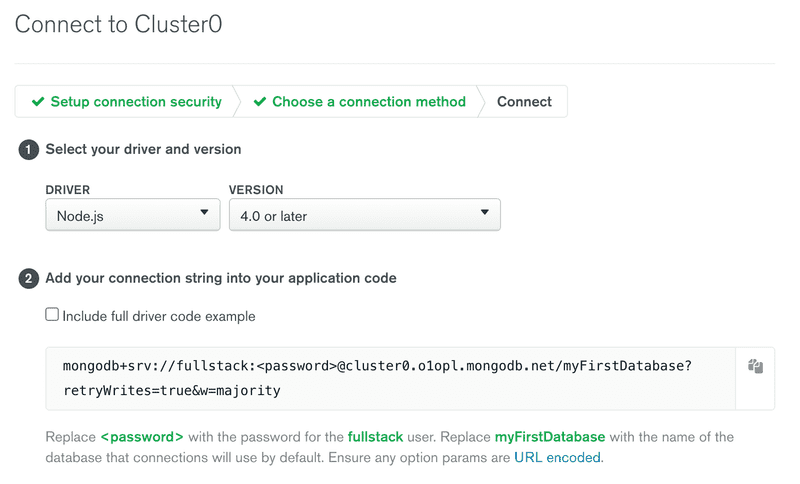
La vue affiche l'URI MongoDB, qui est l'adresse de la base de données que nous allons fournir à la bibliothèque client MongoDB que nous allons ajouter à notre application.
L'adresse ressemble à ceci :
mongodb+srv://fullstack:$thepasswordishere@cluster0.o1opl.mongodb.net/myFirstDatabase?retryWrites=true&w=majorityNous sommes maintenant prêts à utiliser la base de données.
Nous pourrions utiliser la base de données directement depuis notre code JavaScript avec la bibliothèque official MongoDb Node.js driver, mais elle est assez lourde à utiliser. Nous utiliserons plutôt la bibliothèque Mongoose qui offre une API de plus haut niveau.
Mongoose pourrait être décrit comme un object document mapper (ODM), et l'enregistrement d'objets JavaScript en tant que documents Mongo est simple avec cette bibliothèque.
Installons Mongoose :
npm install mongooseN'ajoutons pas encore de code traitant de Mongo à notre backend. Au lieu de cela, faisons une application d'entraînement en créant un nouveau fichier, mongo.js :
const mongoose = require('mongoose')
if (process.argv.length < 3) {
console.log('Please provide the password as an argument: node mongo.js <password>')
process.exit(1)
}
const password = process.argv[2]
const url = `mongodb+srv://notes-app-full:${password}@cluster1.lvvbt.mongodb.net/?retryWrites=true&w=majority`
const noteSchema = new mongoose.Schema({
content: String,
date: Date,
important: Boolean,
})
const Note = mongoose.model('Note', noteSchema)
mongoose
.connect(url)
.then((result) => {
console.log('connected')
const note = new Note({
content: 'HTML is Easy',
date: new Date(),
important: true,
})
return note.save()
})
.then(() => {
console.log('note saved!')
return mongoose.connection.close()
})
.catch((err) => console.log(err))NB: Selon la région que vous avez sélectionnée lors de la construction de votre cluster, l'URI MongoDB peut être différent de l'exemple fourni ci-dessus. Vous devez vérifier et utiliser l'URI correct qui a été généré par l'Atlas MongoDB.
Le code suppose également qu'on lui transmettra le mot de passe des informations d'identification que nous avons créées dans MongoDB Atlas, en tant que paramètre de ligne de commande. Nous pouvons accéder au paramètre de la ligne de commande comme suit :
const password = process.argv[2]Lorsque le code est exécuté avec la commande node mongo.js password, Mongo ajoutera un nouveau document à la base de données.
NB: Veuillez noter que le mot de passe est le mot de passe créé pour l'utilisateur de la base de données, et non votre mot de passe Atlas MongoDB. De plus, si vous avez créé un mot de passe avec des caractères spéciaux, vous devrez coder l'URL de ce mot de passe.
Nous pouvons voir l'état actuel de la base de données dans l'Atlas MongoDB à partir de Browse collections, dans l'onglet Database.
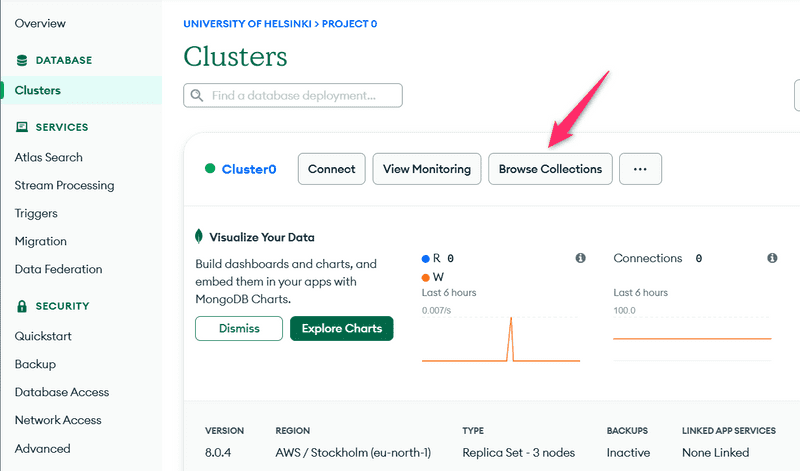
Comme l'indique la vue, le document correspondant à la note a été ajouté à la collection notes de la base de données myFirstDatabase.
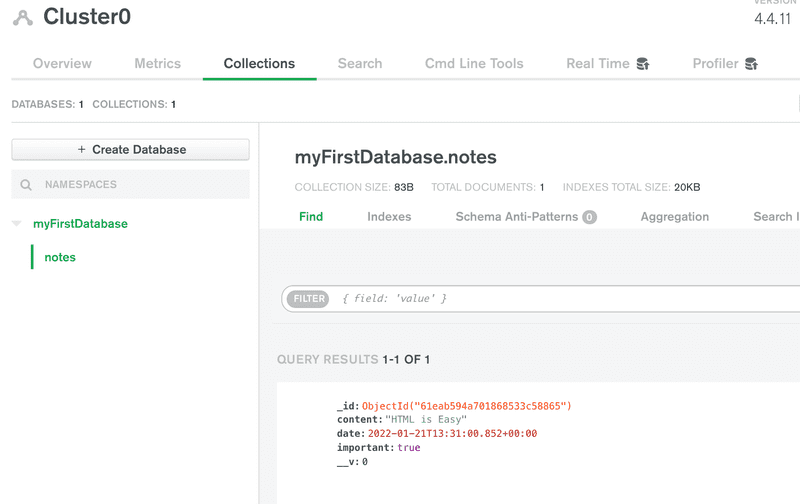
Détruisons la base de données par défaut myFirstDatabase et changeons le nom de la base de données référencée dans notre chaîne de connexion en noteApp à la place, en modifiant l'URI :
mongodb+srv://fullstack:$thepasswordishere@cluster0.o1opl.mongodb.net/noteApp?retryWrites=true&w=majorityExécutons à nouveau notre code :
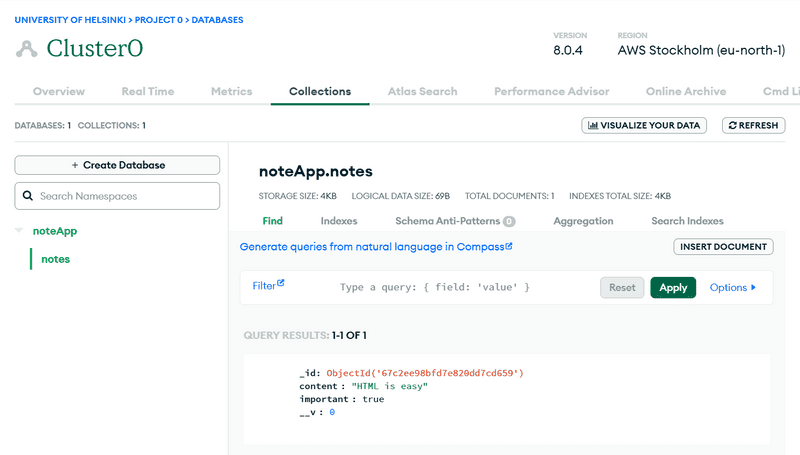
Les données sont maintenant stockées dans la bonne base de données. La vue offre également la fonctionnalité créer une base de données, qui peut être utilisée pour créer de nouvelles bases de données à partir du site Web. Créer la base de données comme ceci n'est pas nécessaire, puisque MongoDB Atlas crée automatiquement une nouvelle base de données lorsqu'une application tente de se connecter à une base de données qui n'existe pas encore.
Schema
Après avoir établi la connexion à la base de données, nous définissons le schéma pour une note et le modèle correspondant :
const noteSchema = new mongoose.Schema({
content: String,
date: Date,
important: Boolean,
})
const Note = mongoose.model('Note', noteSchema)Tout d'abord, nous définissons le schéma d'une note qui est stocké dans la variable noteSchema. Le schéma indique à Mongoose comment les objets note doivent être stockés dans la base de données.
Dans la définition du modèle Note, le premier paramètre "Note" est le nom singulier du modèle. Le nom de la collection sera le pluriel en minuscules notes, car la convention Mongoose consiste à nommer automatiquement les collections au pluriel (par exemple notes) lorsque le schéma les désigne au singulier (par exemple Note).
Les bases de données de documents comme Mongo sont schemaless, ce qui signifie que la base de données elle-même ne se soucie pas de la structure des données qui sont stockées dans la base. Il est possible de stocker des documents avec des champs complètement différents dans la même collection.
L'idée derrière Mongoose est que les données stockées dans la base de données reçoivent un schéma au niveau de l'application qui définit la forme des documents stockés dans toute collection donnée.
Création et sauvegarde d'objets
Ensuite, l'application crée un nouvel objet note à l'aide du Note modèle :
const note = new Note({
content: 'HTML is Easy',
date: new Date(),
important: false,
})Les modèles sont des fonctions dites constructrices qui créent de nouveaux objets JavaScript en fonction des paramètres fournis. Puisque les objets sont créés avec la fonction constructeur du modèle, ils ont toutes les propriétés du modèle, qui incluent des méthodes pour enregistrer l'objet dans la base de données.
L'enregistrement de l'objet dans la base de données s'effectue à l'aide de la méthode save, qui peut être associée à un gestionnaire d'événements avec la méthode then :
note.save().then(result => {
console.log('note saved!')
mongoose.connection.close()
})Lorsque l'objet est enregistré dans la base de données, le gestionnaire d'événements fourni à then est appelé. Le gestionnaire d'événements ferme la connexion à la base de données avec la commande mongoose.connection.close(). Si la connexion n'est pas fermée, le programme ne terminera jamais son exécution.
Le résultat de l'opération de sauvegarde se trouve dans le paramètre result du gestionnaire d'événements. Le résultat n'est pas très intéressant lorsque nous stockons un seul objet dans la base de données. Vous pouvez imprimer l'objet sur la console si vous souhaitez l'examiner de plus près lors de la mise en oeuvre de votre application ou pendant le débogage.
Prenons également quelques notes supplémentaires en modifiant les données dans le code et en exécutant à nouveau le programme.
NB: Malheureusement, la documentation de Mongoose n'est pas très cohérente, certaines parties utilisant les callbacks dans leurs exemples et d'autres parties, d'autres styles, il n'est donc pas recommandé de copier-coller du code directement à partir de là. Il n'est pas recommandé de mélanger les promesses avec les callbacks de la vieille école dans le même code.
Récupération d'objets dans la base de données
Mettons en commentaire le code pour générer de nouvelles notes et remplaçons-le par ce qui suit :
Note.find({}).then(result => {
result.forEach(note => {
console.log(note)
})
mongoose.connection.close()
})Lorsque le code est exécuté, le programme imprime toutes les notes stockées dans la base de données :
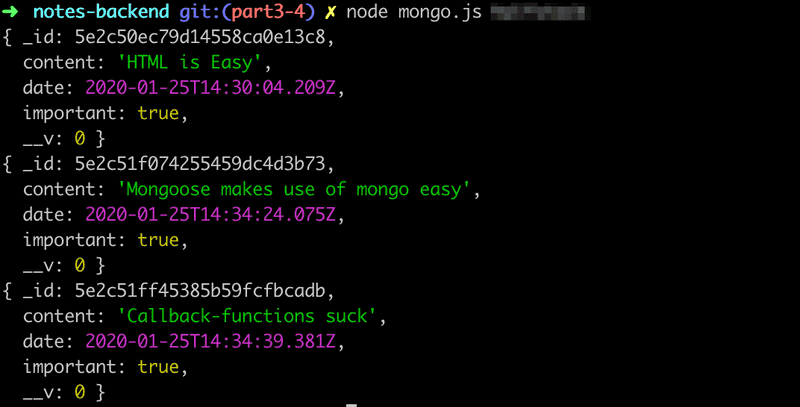
Les objets sont récupérés dans la base de données avec la méthode find du modèle Note. Le paramètre de la méthode est un objet exprimant les conditions de recherche. Comme le paramètre est un objet vide{}, nous obtenons toutes les notes stockées dans la collection notes.
Les conditions de recherche sont conformes à la requête de recherche Mongo syntaxe.
Nous pourrions restreindre notre recherche pour n'inclure que les notes importantes comme ceci :
Note.find({ important: true }).then(result => {
// ...
})Backend connecté à une base de données
Maintenant, nous avons suffisamment de connaissances pour commencer à utiliser Mongo dans notre application.
Commençons rapidement en copiant-collant les définitions de Mongoose dans le fichier index.js :
const mongoose = require('mongoose')
// Assigns the second command line argument to 'password'
const password = process.argv[2];
// DO NOT SAVE YOUR PASSWORD TO GITHUB!!
const url =
`mongodb+srv://fullstack:thepasswordishere@cluster0.o1opl.mongodb.net/noteApp?retryWrites=true&w=majority`
mongoose.connect(url)
const noteSchema = new mongoose.Schema({
content: String,
date: Date,
important: Boolean,
})
const Note = mongoose.model('Note', noteSchema)Modifions le gestionnaire pour récupérer toutes les notes sous la forme suivante :
app.get('/api/notes', (request, response) => {
Note.find({}).then(notes => {
response.json(notes)
})
})Nous pouvons vérifier dans le navigateur que le backend fonctionne pour l'affichage de tous les documents :
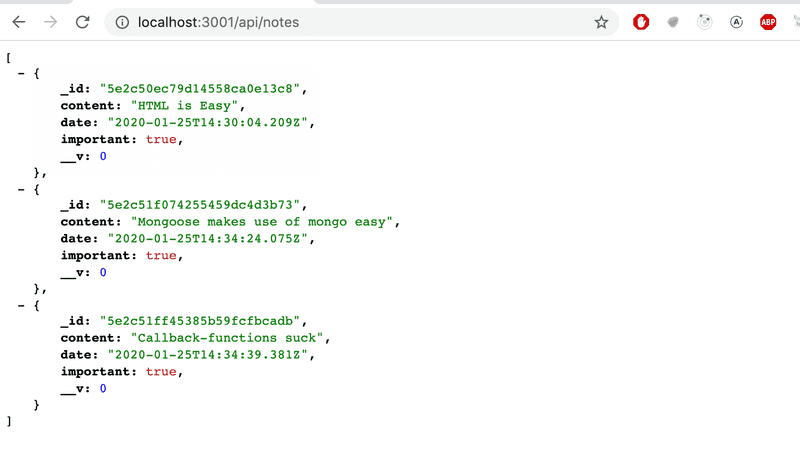
L'application fonctionne presque parfaitement. Le frontend suppose que chaque objet a un id unique dans le champ id. Nous ne voulons pas non plus renvoyer le champ de versioning mongo __v au frontend.
Une façon de formater les objets retournés par Mongoose est de modifier la méthode toJSON du schéma, qui est utilisée sur toutes les instances des modèles produits avec ce schéma. La modification de la méthode fonctionne comme suit :
noteSchema.set('toJSON', {
transform: (document, returnedObject) => {
returnedObject.id = returnedObject._id.toString()
delete returnedObject._id
delete returnedObject.__v
}
})Même si la propriété _id des objets Mongoose ressemble à une chaîne, il s'agit en fait d'un objet. La méthode toJSON que nous avons définie la transforme en chaîne de caractères par mesure de sécurité. Si nous ne faisions pas ce changement, cela nous causerait plus de tort à l'avenir, lorsque nous commencerons à écrire des tests.
Répondons à la requête HTTP avec une liste d'objets formatés avec la méthode toJSON :
app.get('/api/notes', (request, response) => {
Note.find({}).then(notes => {
response.json(notes)
})
})Maintenant la variable notes est assignée à un tableau d'objets retournés par Mongo. Lorsque la réponse est envoyée au format JSON, la méthode toJSON de chaque objet du tableau est appelée automatiquement par la méthode JSON.stringify.
La configuration de la base de données dans son propre module
Avant de refactoriser le reste du backend pour utiliser la base de données, extrayons le code spécifique à Mongoose dans son propre module.
Créons un nouveau répertoire pour le module appelé models, et ajoutons un fichier appelé note.js :
const mongoose = require('mongoose')
const url = process.env.MONGODB_URI
console.log('connecting to', url)
mongoose.connect(url)
.then(result => { console.log('connected to MongoDB') }) .catch((error) => { console.log('error connecting to MongoDB:', error.message) })
const noteSchema = new mongoose.Schema({
content: String,
date: Date,
important: Boolean,
})
noteSchema.set('toJSON', {
transform: (document, returnedObject) => {
returnedObject.id = returnedObject._id.toString()
delete returnedObject._id
delete returnedObject.__v
}
})
module.exports = mongoose.model('Note', noteSchema)La définition des [modules] de Node (https://nodejs.org/docs/latest-v8.x/api/modules.html) diffère légèrement de la manière de définir les modules ES6 dans la partie 2.
L'interface publique du module est définie en attribuant une valeur à la variable module.exports. Nous allons définir la valeur comme étant le modèle Note. Les autres choses définies à l'intérieur du module, comme les variables mongoose et url ne seront pas accessibles ou visibles pour les utilisateurs du module.
L'importation du module se fait en ajoutant la ligne suivante à index.js :
const Note = require('./models/note')De cette façon, la variable Note sera affectée au même objet que celui défini par le module.
La façon dont la connexion est établie a légèrement changé :
const url = process.env.MONGODB_URI
console.log('connecting to', url)
mongoose.connect(url)
.then(result => {
console.log('connected to MongoDB')
})
.catch((error) => {
console.log('error connecting to MongoDB:', error.message)
})Ce n'est pas une bonne idée de coder en dur l'adresse de la base de données dans le code, donc à la place l'adresse de la base de données est transmise à l'application via la variable d'environnement MONGODB_URI.
La méthode d'établissement de la connexion est maintenant dotée de fonctions permettant de traiter une tentative de connexion réussie ou non. Les deux fonctions se contentent de consigner un message dans la console concernant l'état de réussite :

Il existe de nombreuses façons de définir la valeur d'une variable d'environnement. L'une d'elles consiste à la définir au démarrage de l'application :
MONGODB_URI=address_here npm run devUne méthode plus sophistiquée consiste à utiliser la bibliothèque dotenv. Vous pouvez installer la bibliothèque avec la commande :
npm install dotenvPour utiliser la bibliothèque, nous créons un fichier .env à la racine du projet. Les variables d'environnement sont définies à l'intérieur du fichier, et il peut ressembler à ceci :
MONGODB_URI=mongodb+srv://fullstack:thepasswordishere@cluster0.o1opl.mongodb.net/noteApp?retryWrites=true&w=majority
PORT=3001Nous avons également ajouté le port en dur du serveur dans la variable d'environnement PORT.
Le fichier .env doit être gitignoré tout de suite, car nous ne voulons pas publier d'informations confidentielles publiquement en ligne !

Les variables d'environnement définies dans le fichier .env peuvent être prises en compte avec l'expression require('dotenv').config() et vous pouvez les référencer dans votre code comme vous référeriez des variables d'environnement normales, avec la syntaxe familière process.env.MONGODB_URI.
Modifions le fichier index.js de la manière suivante :
require('dotenv').config()const express = require('express')
const app = express()
const Note = require('./models/note')
// ..
const PORT = process.env.PORTapp.listen(PORT, () => {
console.log(`Server running on port ${PORT}`)
})Il est important que dotenv soit importé avant que le modèle note soit importé. Cela garantit que les variables d'environnement du fichier .env sont disponibles globalement avant que le code des autres modules ne soit importé.
Une fois que le fichier .env a été gitignoré, Heroku ne récupère pas l'url de la base de données à partir du référentiel, vous devez donc le définir vous-même. Cela peut être fait via le tableau de bord Heroku comme suit :
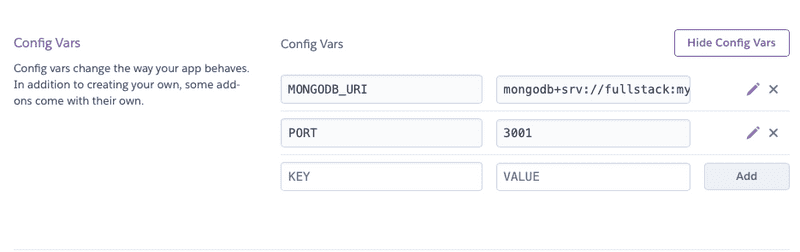
ou depuis la ligne de commande avec la commande :
heroku config:set MONGODB_URI='mongodb+srv://fullstack:thepasswordishere@cluster0.o1opl.mongodb.net/noteApp?retryWrites=true&w=majority'Utilisation de la base de données dans les gestionnaires de route
Ensuite, changeons le reste de la fonctionnalité du backend pour utiliser la base de données.
La création d'une nouvelle note se fait comme suit :
app.post('/api/notes', (request, response) => {
const body = request.body
if (body.content === undefined) {
return response.status(400).json({ error: 'content missing' })
}
const note = new Note({
content: body.content,
important: body.important || false,
date: new Date(),
})
note.save().then(savedNote => {
response.json(savedNote)
})
})Les objets note sont créés avec la fonction constructrice Note. La réponse est envoyée dans la fonction de rappel de l'opération save. Cela garantit que la réponse n'est envoyée que si l'opération a réussi. Nous aborderons la gestion des erreurs un peu plus tard.
Le paramètre savedNote de la fonction de rappel est la note sauvegardée et nouvellement créée. Les données renvoyées dans la réponse sont la version formatée créée avec la méthode toJSON :
response.json(savedNote)En utilisant la méthode findById de Mongoose, la récupération d'une note individuelle se transforme en ce qui suit :
app.get('/api/notes/:id', (request, response) => {
Note.findById(request.params.id).then(note => {
response.json(note)
})
})Vérification de l'intégration du front-end et du back-end
Lorsque le backend est étendu, c'est une bonne idée de tester d'abord le backend avec le navigateur, Postman ou le client REST de VS Code. Ensuite, essayons de créer une nouvelle note après avoir pris en compte la base de données :
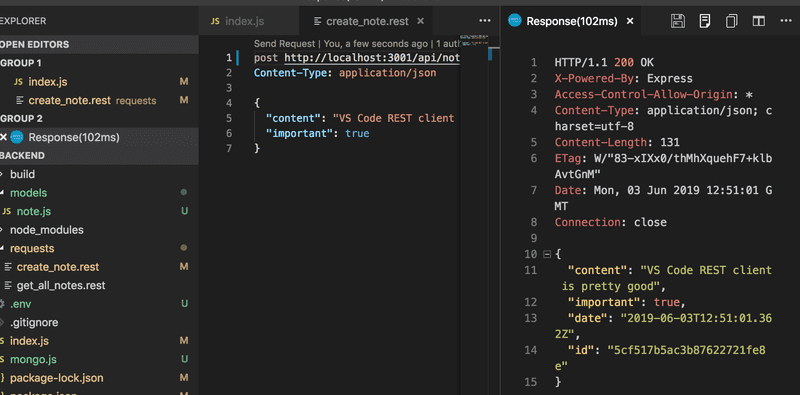
Ce n'est qu'une fois que l'on a vérifié que tout fonctionne dans le backend, qu'il est bon de tester que le frontend fonctionne avec le backend. Il est très inefficace de tester les choses exclusivement par le biais du frontend.
C'est probablement une bonne idée d'intégrer le frontend et le backend une fonctionnalité à la fois. Tout d'abord, nous pourrions implémenter la récupération de toutes les notes de la base de données et la tester via le point de terminaison du backend dans le navigateur. Ensuite, nous pourrions vérifier que le frontend fonctionne avec le nouveau backend. Une fois que tout semble fonctionner, nous pourrions passer à la fonctionnalité suivante.
Une fois que nous introduisons une base de données dans le mélange, il est utile d'inspecter l'état persistant dans la base de données, par exemple à partir du panneau de contrôle dans MongoDB Atlas. Très souvent, de petits programmes d'aide Node comme le programme mongo.js que nous avons écrit précédemment peuvent être très utiles pendant le développement.
Vous pouvez trouver le code de notre application actuelle dans son intégralité dans la branche part3-4 de ce dépôt GitHub.
Traitement des erreurs
Si nous essayons de visiter l'URL d'une note avec un id qui n'existe pas réellement, par exemple http://localhost:3001/api/notes/5c41c90e84d891c15dfa3431 où 5c41c90e84d891c15dfa3431 n'est pas un id stocké dans la base de données, alors la réponse sera null.
Changeons ce comportement pour que si la note avec l'id donné n'existe pas, le serveur répondra à la requête avec le code de statut HTTP 404 not found. En outre, implémentons un simple bloc catch pour gérer les cas où la promesse retournée par la méthode findById est rejetée :
app.get('/api/notes/:id', (request, response) => {
Note.findById(request.params.id)
.then(note => {
if (note) { response.json(note) } else { response.status(404).end() } })
.catch(error => { console.log(error) response.status(500).end() })})Si aucun objet correspondant n'est trouvé dans la base de données, la valeur de note sera null et le bloc else sera exécuté. Il en résulte une réponse avec le code d'état 404 not found. Si la promesse renvoyée par la méthode findById est rejetée, la réponse aura le code d'état 500 internal server error. La console affiche des informations plus détaillées sur l'erreur.
En plus de la note inexistante, il y a une autre situation d'erreur qui doit être traitée. Dans cette situation, nous essayons de récupérer une note avec un mauvais type d'id, c'est-à-dire un id qui ne correspond pas au format d'identifiant mongo.
Si nous effectuons la requête suivante, nous obtiendrons le message d'erreur indiqué ci-dessous :
Method: GET
Path: /api/notes/someInvalidId
Body: {}
---
{ CastError: Cast to ObjectId failed for value "someInvalidId" at path "_id"
at CastError (/Users/mluukkai/opetus/_fullstack/osa3-muisiinpanot/node_modules/mongoose/lib/error/cast.js:27:11)
at ObjectId.cast (/Users/mluukkai/opetus/_fullstack/osa3-muisiinpanot/node_modules/mongoose/lib/schema/objectid.js:158:13)
...Étant donné un id malformé comme argument, la méthode findById lancera une erreur provoquant le rejet de la promesse retournée. Cela provoquera l'appel de la fonction callback définie dans le bloc catch.
Faisons quelques petits ajustements à la réponse dans le bloc catch :
app.get('/api/notes/:id', (request, response) => {
Note.findById(request.params.id)
.then(note => {
if (note) {
response.json(note)
} else {
response.status(404).end()
}
})
.catch(error => {
console.log(error)
response.status(400).send({ error: 'malformatted id' }) })
})Si le format de l'identifiant est incorrect, nous nous retrouverons dans le gestionnaire d'erreur défini dans le bloc catch. Le code d'état approprié pour cette situation est 400 Bad Request, car la situation correspond parfaitement à la description :
La demande n'a pas pu être comprise par le serveur en raison d'une syntaxe malformée. Le client NE DEVRAIT PAS répéter la demande sans modifications.
Nous avons également ajouté quelques données à la réponse pour faire la lumière sur la cause de l'erreur.
Lorsque vous traitez avec des Promesses, c'est presque toujours une bonne idée d'ajouter la gestion des erreurs et des exceptions, car sinon vous vous retrouverez à traiter des bugs étranges.
Ce n'est jamais une mauvaise idée d'imprimer l'objet qui a causé l'exception sur la console dans le gestionnaire d'erreur :
.catch(error => {
console.log(error) response.status(400).send({ error: 'malformatted id' })
})La raison pour laquelle le gestionnaire d'erreurs est appelé peut être complètement différente de ce que vous aviez prévu. Si vous consignez l'erreur dans la console, vous vous épargnerez de longues et frustrantes sessions de débogage. En outre, la plupart des services modernes sur lesquels vous déployez votre application prennent en charge une certaine forme de système de journalisation que vous pouvez utiliser pour vérifier ces journaux. Comme nous l'avons mentionné, Heroku en est un.
Chaque fois que vous travaillez sur un projet avec un backend, il est essentiel de garder un oeil sur la sortie console du backend. Si vous travaillez sur un petit écran, il suffit de voir une toute petite tranche de la sortie en arrière-plan. Tout message d'erreur attirera votre attention même si la console est loin en arrière-plan :
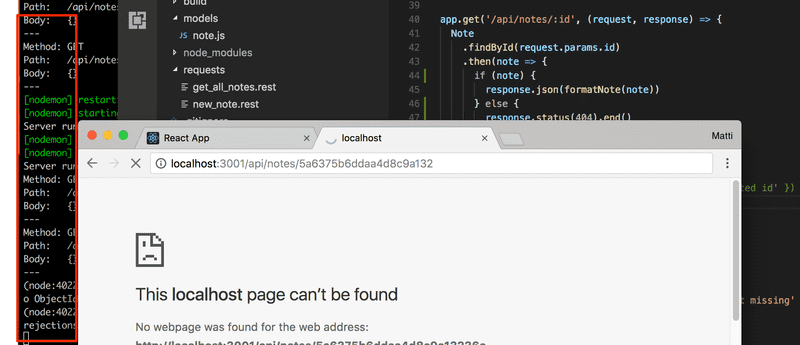
Déplacer la gestion des erreurs dans le middleware
Nous avons écrit le code pour le gestionnaire d'erreurs parmi le reste de notre code. Cela peut être une solution raisonnable à certains moments, mais il y a des cas où il est préférable d'implémenter toute la gestion des erreurs à un seul endroit. Cela peut s'avérer particulièrement utile si nous souhaitons par la suite transmettre les données relatives aux erreurs à un système externe de suivi des erreurs comme Sentry.
Modifions le gestionnaire de la route /api/notes/:id, afin qu'il transmette l'erreur avec la fonction next. La fonction next est passée au handler comme troisième paramètre :
app.get('/api/notes/:id', (request, response, next) => { Note.findById(request.params.id)
.then(note => {
if (note) {
response.json(note)
} else {
response.status(404).end()
}
})
.catch(error => next(error))})L'erreur qui est transmise en amont est donnée à la fonction next en tant que paramètre. Si next était appelée sans paramètre, alors l'exécution passerait simplement à la route ou au middleware suivant. Si la fonction next est appelée avec un paramètre, alors l'exécution se poursuivra jusqu'au milieu de traitement des erreurs.
Les error handlers d'express sont des middlewares qui sont définis avec une fonction qui accepte quatre paramètres. Notre gestionnaire d'erreur ressemble à ceci :
const errorHandler = (error, request, response, next) => {
console.error(error.message)
if (error.name === 'CastError') {
return response.status(400).send({ error: 'malformatted id' })
}
next(error)
}
// this has to be the last loaded middleware.
app.use(errorHandler)Le gestionnaire d'erreur vérifie si l'erreur est une exception CastError, auquel cas nous savons que l'erreur a été causée par un id d'objet invalide pour Mongo. Dans cette situation, le gestionnaire d'erreur enverra une réponse au navigateur avec l'objet de réponse passé en paramètre. Dans toutes les autres situations d'erreur, le middleware transmet l'erreur au gestionnaire d'erreur Express par défaut.
Notez que le middleware de gestion des erreurs doit être le dernier middleware chargé !
L'ordre de chargement des middlewares
L'ordre d'exécution des middlewares est le même que l'ordre dans lequel ils sont chargés dans Express avec la fonction app.use. Pour cette raison, il est important d'être prudent lors de la définition des middlewares.
L'ordre correct est le suivant :
app.use(express.static('build'))
app.use(express.json())
app.use(requestLogger)
app.post('/api/notes', (request, response) => {
const body = request.body
// ...
})
const unknownEndpoint = (request, response) => {
response.status(404).send({ error: 'unknown endpoint' })
}
// handler of requests with unknown endpoint
app.use(unknownEndpoint)
const errorHandler = (error, request, response, next) => {
// ...
}
// handler of requests with result to errors
app.use(errorHandler)Le middleware json-parser devrait être parmi les tout premiers middleware chargés dans Express. Si l'ordre était le suivant :
app.use(requestLogger) // request.body is undefined!
app.post('/api/notes', (request, response) => {
// request.body is undefined!
const body = request.body
// ...
})
app.use(express.json())Les données JSON envoyées avec les requêtes HTTP ne seraient alors pas disponibles pour le middleware du logger ou le gestionnaire de route POST, puisque le request.body serait undefined à ce moment-là.
Il est également important que le middleware de gestion des routes non prises en charge soit le dernier middleware chargé dans Express, juste avant le gestionnaire d'erreurs.
Par exemple, l'ordre de chargement suivant causerait un problème :
const unknownEndpoint = (request, response) => {
response.status(404).send({ error: 'unknown endpoint' })
}
// handler of requests with unknown endpoint
app.use(unknownEndpoint)
app.get('/api/notes', (request, response) => {
// ...
})Maintenant, le traitement des points de terminaison inconnus est ordonné avant le gestionnaire de requête HTTP. Puisque le gestionnaire de points de terminaison inconnus répond à toutes les demandes avec 404 unknown endpoint, aucune route ou middleware ne sera appelée après que la réponse ait été envoyée par le middleware de points de terminaison inconnus. La seule exception à cela est le gestionnaire d'erreur qui doit venir à la toute fin, après le gestionnaire de points de terminaison inconnus.
Autres opérations
Ajoutons quelques fonctionnalités manquantes à notre application, notamment la suppression et la mise à jour d'une note individuelle.
La façon la plus simple de supprimer une note de la base de données est d'utiliser la méthode findByIdAndDelete :
app.delete('/api/notes/:id', (request, response, next) => {
Note.findByIdAndDelete(request.params.id)
.then(result => {
response.status(204).end()
})
.catch(error => next(error))
})Dans les deux cas de "réussite" de la suppression d'une ressource, le backend répond avec le code d'état 204 no content. Les deux cas différents sont la suppression d'une note qui existe, et la suppression d'une note qui n'existe pas dans la base de données. Le paramètre de callback result pourrait être utilisé pour vérifier si une ressource a effectivement été supprimée, et nous pourrions utiliser cette information pour renvoyer des codes d'état différents pour les deux cas si nous le jugions nécessaire. Toute exception qui se produit est transmise au gestionnaire d'erreurs.
Le changement de l'importance d'une note peut être facilement réalisé avec la méthode findByIdAndUpdate.
app.put('/api/notes/:id', (request, response, next) => {
const body = request.body
const note = {
content: body.content,
important: body.important,
}
Note.findByIdAndUpdate(request.params.id, note, { new: true })
.then(updatedNote => {
response.json(updatedNote)
})
.catch(error => next(error))
})Dans le code ci-dessus, nous permettons également de modifier le contenu de la note. Cependant, nous ne prendrons pas en charge la modification de la date de création pour des raisons évidentes.
Remarquez que la méthode findByIdAndUpdate reçoit un objet JavaScript ordinaire comme paramètre, et non un nouvel objet note créé avec la fonction constructeur Note.
Il existe un détail important concernant l'utilisation de la méthode findByIdAndUpdate. Par défaut, le paramètre updatedNote du gestionnaire d'événements reçoit le document original sans les modifications. Nous avons ajouté le paramètre optionnel { new : true }, qui fera en sorte que notre gestionnaire d'événements soit appelé avec le nouveau document modifié au lieu de l'original.
Après avoir testé le backend directement avec Postman et le client REST de VS Code, nous pouvons vérifier qu'il semble fonctionner. Le frontend semble également fonctionner avec le backend en utilisant la base de données.
Vous pouvez trouver le code de notre application actuelle dans son intégralité dans la branche part3-5 de ce dépôt GitHub.
Exercices 3.15.-3.18.
3.15 : Base de données du répertoire téléphonique, étape3
Modifiez le backend pour que la suppression des entrées du répertoire téléphonique soit répercutée dans la base de données.
Vérifiez que le frontend fonctionne toujours après avoir fait les changements.
3.16 : Base de données du répertoire téléphonique, étape 4
Déplacer la gestion des erreurs de l'application vers un nouveau middleware de gestion des erreurs.
3.17* : Base de données du répertoire téléphonique, étape 5
Si l'utilisateur essaie de créer une nouvelle entrée dans le répertoire pour une personne dont le nom est déjà dans le répertoire, le frontend va essayer de mettre à jour le numéro de téléphone de l'entrée existante en faisant une requête HTTP PUT à l'URL unique de l'entrée.
Modifiez le backend pour supporter cette requête.
Vérifiez que le frontend fonctionne après avoir fait vos changements.
3.18* : Base de données du répertoire téléphonique étape6
Mettez également à jour la gestion des routes api/persons/:id et info pour utiliser la base de données, et vérifiez qu'elles fonctionnent directement avec le navigateur, Postman, ou le client REST de VS Code.
L'inspection d'une entrée de répertoire individuelle depuis le navigateur devrait ressembler à ceci :
