e
Fragmentos y suscripciones
Nos acercamos al final del curso. Terminemos echando un vistazo a algunos detalles más de GraphQL.
fragmentos
Es bastante común en GraphQL que múltiples consultas devuelvan resultados similares. Por ejemplo, la consulta para los detalles de una persona
query {
findPerson(name: "Pekka Mikkola") {
name
phone
address{
street
city
}
}
}y la consulta para todas las personas
query {
allPersons {
name
phone
address{
street
city
}
}
}ambas regresan personas. Al elegir los campos a devolver, ambas consultas deben definir exactamente los mismos campos.
Este tipo de situaciones se pueden simplificar con el uso de fragmentos. Declaremos un fragmento para seleccionar todos los campos de una persona:
fragment PersonDetails on Person {
name
phone
address {
street
city
}
}Con el fragment podemos hacer las consultas en forma compacta:
query {
allPersons {
...PersonDetails }
}
query {
findPerson(name: "Pekka Mikkola") {
...PersonDetails }
}Los fragmentos son no definidos en el esquema GraphQL, sino en el cliente. Los fragmentos deben declararse cuando el cliente los utilice para consultas.
En principio, podríamos declarar el fragmento con cada consulta de la siguiente manera:
const ALL_PERSONS = gql`
{
allPersons {
...PersonDetails
}
}
fragment PersonDetails on Person {
name
phone
address {
street
city
}
}
`Sin embargo, es mucho mejor declarar el fragmento una vez y guardarlo en una variable.
const PERSON_DETAILS = gql`
fragment PersonDetails on Person {
id
name
phone
address {
street
city
}
}
`Declarado así, el fragmento se puede colocar en cualquier consulta o mutación usando un signo de dólar y llaves:
const ALL_PERSONS = gql`
{
allPersons {
...PersonDetails
}
}
${PERSON_DETAILS}
`Suscripciones
Junto con los tipos de consulta y mutación, GraphQL ofrece un tercer tipo de operación: suscripciones. Con las suscripciones, los clientes pueden suscribirse a actualizaciones sobre cambios en el servidor.
Las suscripciones son radicalmente diferentes a todo lo que hemos visto en este curso hasta ahora. Hasta ahora, toda la interacción entre el navegador y el servidor ha sido la aplicación React en el navegador que realiza solicitudes HTTP al servidor. Las consultas y mutaciones de GraphQL también se han realizado de esta manera. Con las suscripciones la situación es la contraria. Una vez que una aplicación se ha suscrito, comienza a escuchar al servidor. Cuando ocurren cambios en el servidor, envía una notificación a todos sus suscriptores.
Técnicamente hablando, el protocolo HTTP no es adecuado para la comunicación desde el servidor al navegador, por lo que Apollo usa WebSockets para la comunicación del suscriptor del servidor.
Suscripciones en el servidor
Implementemos suscripciones para suscribirse a notificaciones sobre nuevas personas agregadas.
No hay muchos cambios en el servidor. El esquema cambia así:
type Subscription {
personAdded: Person!
} Entonces, cuando se agrega una nueva persona, todos sus detalles se envían a todos los suscriptores.
La suscripción personAdded necesita un solucionador. El solucionador addPerson también debe modificarse para que envíe una notificación a los suscriptores.
Los cambios requeridos son los siguientes:
const { PubSub } = require('graphql-subscriptions')const pubsub = new PubSub()
Mutation: {
addPerson: async (root, args, context) => {
const person = new Person({ ...args })
const currentUser = context.currentUser
if (!currentUser) {
throw new AuthenticationError("not authenticated")
}
try {
await person.save()
currentUser.friends = currentUser.friends.concat(person)
await currentUser.save()
} catch (error) {
throw new UserInputError(error.message, {
invalidArgs: args,
})
}
pubsub.publish('PERSON_ADDED', { personAdded: person })
return person
},
},
Subscription: { personAdded: { subscribe: () => pubsub.asyncIterableIterator(['PERSON_ADDED']) }, },Con las suscripciones, la comunicación ocurre usando el principio publicar-suscribir utilizando un objeto usando un PubSub interfaz. Agregar una nueva persona publica una notificación sobre la operación a todos los suscriptores con el método publish de PubSub.
personAdded subscriptions resolver registra a todos los suscriptores devolviéndoles un objeto iterador adecuado .
Hagamos los siguientes cambios en el código que inicia el servidor
// ...
server.listen().then(({ url, subscriptionsUrl }) => { console.log(`Server ready at ${url}`)
console.log(`Subscriptions ready at ${subscriptionsUrl}`)})Vemos que el servidor escucha suscripciones en la dirección ws://localhost:4000/graphql
Server ready at http://localhost:4000/
Subscriptions ready at ws://localhost:4000/graphqlNo se necesitan otros cambios en el servidor.
Es posible probar las suscripciones con el patio de juegos de GraphQL de esta manera:
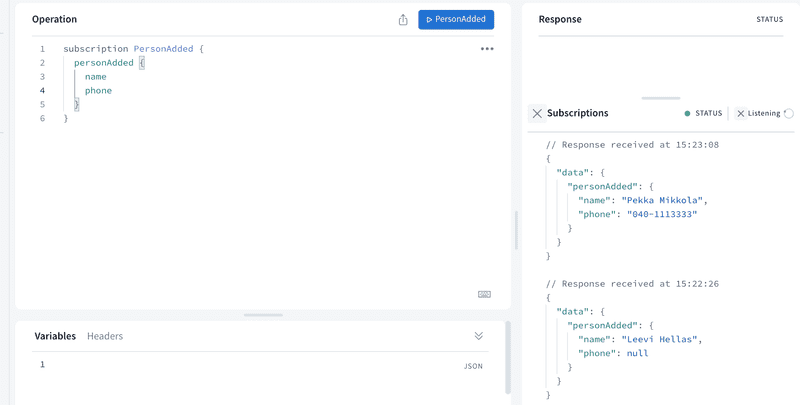
Cuando presiona "reproducir" en una suscripción, el área de juegos espera las notificaciones de la suscripción.
El código de backend se puede encontrar en Github, rama part8-6.
Suscripciones en el cliente
Para usar suscripciones en nuestra aplicación React, tenemos que hacer algunos cambios, especialmente en su configuración. La configuración en index.js tiene que ser modificada así:
import {
ApolloClient, HttpLink, InMemoryCache,
split} from '@apollo/client'
import { ApolloProvider } from '@apollo/client/react'
import { setContext } from 'apollo-link-context'
import { getMainDefinition } from '@apollo/client/utilities'import { WebSocketLink } from '@apollo/client/link/ws'
const authLink = setContext((_, { headers }) => {
const token = localStorage.getItem('phonenumbers-user-token')
return {
headers: {
...headers,
authorization: token ? `bearer ${token}` : null,
}
}
})
const httpLink = new HttpLink({
uri: 'http://localhost:4000',
})
const wsLink = new WebSocketLink({ uri: `ws://localhost:4000/graphql`, options: { reconnect: true }})const splitLink = split( ({ query }) => { const definition = getMainDefinition(query) return ( definition.kind === 'OperationDefinition' && definition.operation === 'subscription' ); }, wsLink, authLink.concat(httpLink),)
const client = new ApolloClient({
cache: new InMemoryCache(),
link: splitLink})
ReactDOM.render(
<ApolloProvider client={client}>
<App />
</ApolloProvider>,
document.getElementById('root')
)Para que esto funcione, tenemos que instalar algunas dependencias:
npm install @apollo/client subscriptions-transport-wsLa nueva configuración se debe al hecho de que la aplicación debe tener una conexión HTTP así como una conexión WebSocket al servidor GraphQL.
const wsLink = new WebSocketLink({
uri: `ws://localhost:4000/graphql`,
options: { reconnect: true }
})
const httpLink = createHttpLink({
uri: 'http://localhost:4000',
})Las suscripciones se realizan utilizando la función de gancho useSubscription.
Modifiquemos el código así:
export const PERSON_ADDED = gql` subscription { personAdded { ...PersonDetails } } ${PERSON_DETAILS}`
import {
useQuery, useMutation, useSubscription, useApolloClient} from '@apollo/client/react'
const App = () => {
// ...
useSubscription(PERSON_ADDED, {
onData: ({ data }) => {
console.log(data)
}
})
// ...
}Cuando se agrega una nueva persona a la agenda, no independientemente de dónde se haga, los detalles de la nueva persona se imprimen en la consola del cliente:
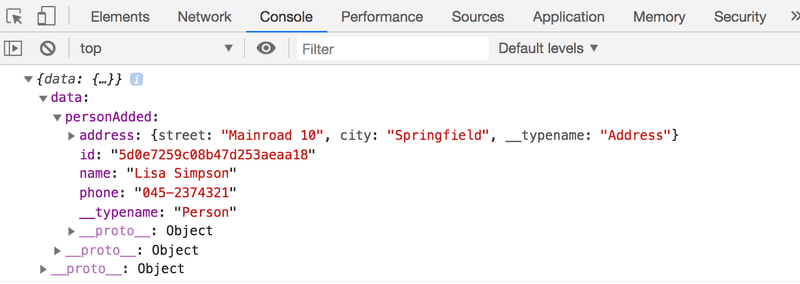
Cuando se agrega una nueva persona, el servidor envía una notificación al cliente y se llama a la función de devolución de llamada definida en el atributo onData y se le dan los detalles. de la nueva persona como parámetros.
Extendamos nuestra solución para que cuando se reciban los detalles de una nueva persona, la persona se agregue a la caché de Apollo, de modo que se muestre en la pantalla de inmediato.
Sin embargo, debemos tener en cuenta que cuando nuestra aplicación crea una nueva persona, no se debe agregar a la caché dos veces:
const App = () => {
// ...
const updateCacheWith = (addedPerson) => {
const includedIn = (set, object) =>
set.map(p => p.id).includes(object.id)
const dataInStore = client.readQuery({ query: ALL_PERSONS })
if (!includedIn(dataInStore.allPersons, addedPerson)) {
client.writeQuery({
query: ALL_PERSONS,
data: { allPersons : dataInStore.allPersons.concat(addedPerson) }
})
}
}
useSubscription(PERSON_ADDED, {
onData: ({ data }) => {
const addedPerson = data.data.personAdded
notify(`${addedPerson.name} added`)
updateCacheWith(addedPerson)
}
})
// ...
}La función updateCacheWith también se puede utilizar en PersonForm para la actualización de la caché:
const PersonForm = ({ setError, updateCacheWith }) => { // ...
const [ createPerson ] = useMutation(CREATE_PERSON, {
onError: (error) => {
setError(error.graphQLErrors[0].message)
},
update: (store, response) => {
updateCacheWith(response.data.addPerson) }
})
// ..
} El código final del cliente puede ser que se encuentra en Github, rama part8-9.
problema n+1
Agreguemos algunas cosas al backend. Modifiquemos el esquema para que un tipo Person tenga un campo friendOf, que indica en qué lista de amigos está la persona.
type Person {
name: String!
phone: String
address: Address!
friendOf: [User!]!
id: ID!
}La aplicación debe admitir la siguiente consulta:
query {
findPerson(name: "Leevi Hellas") {
friendOf{
username
}
}
}Debido a que friendOf no es un campo de objetos Person en la base de datos, tenemos que crear un solucionador para él, que puede resolver este problema. Primero creemos un resolutor que devuelva una lista vacía:
Person: {
address: (root) => {
return {
street: root.street,
city: root.city
}
},
friendOf: (root) => { // return list of users return [ ] }},El parámetro root es el objeto de persona cuya lista de amigos se está creando, por lo que buscamos entre todos los objetos User los que tienen root._id en su lista de amigos:
Person: {
// ...
friendOf: async (root) => {
const friends = await User.find({
friends: {
$in: [root._id]
}
})
return friends
}
},Ahora la aplicación funciona.
Inmediatamente podemos hacer consultas aún más complicadas. Es posible, por ejemplo, encontrar los amigos de todos los usuarios:
query {
allPersons {
name
friendOf {
username
}
}
}Sin embargo, hay un problema con nuestra solución, hace una cantidad irrazonable de consultas a la base de datos. Si registramos todas las consultas en la base de datos y tenemos 5 personas guardadas, vemos lo siguiente:
Person.find
User.find
User.find
User.find
User.find
User.findAsí que aunque principalmente hacen una consulta para todas las personas, cada persona genera una consulta más en su resolución.
Esta es una manifestación del famoso n+1-problema, que aparece de vez en cuando en diferentes contextos y, a veces, se cuela sobre los desarrolladores sin que se den cuenta.
Una buena solución para el problema n + 1 depende de la situación. A menudo, requiere el uso de algún tipo de consulta de combinación en lugar de varias consultas independientes.
En nuestra situación, la solución más fácil sería guardar la lista de amigos en la que se encuentran en cada objeto Person:
const schema = new mongoose.Schema({
name: {
type: String,
required: true,
unique: true,
minlength: 5
},
phone: {
type: String,
minlength: 5
},
street: {
type: String,
required: true,
minlength: 5
},
city: {
type: String,
required: true,
minlength: 5
},
friendOf: [ { type: mongoose.Schema.Types.ObjectId, ref: 'User' } ], })Entonces podríamos hacer una "consulta de unión", o rellenar los campos friendOf de personas cuando buscamos los objetos Person:
Query: {
allPersons: (root, args) => {
console.log('Person.find')
if (!args.phone) {
return Person.find({}).populate('friendOf') }
return Person.find({ phone: { $exists: args.phone === 'YES' } })
.populate('friendOf') },
// ...
}Después del cambio, no necesitaríamos un solucionador separado para el campo friendOf.
La consulta allPersons no causa un problema n + 1, si solo obtenemos el nombre y el número de teléfono:
query {
allPersons {
name
phone
}
}Si modificamos allPersons para hacer una consulta de combinación porque a veces causa un problema n + 1, se vuelve más pesado cuando no necesitamos la información sobre personas relacionadas. Al usar el cuarto parámetro de las funciones de resolución, podríamos optimizar la consulta aún más. El cuarto parámetro se puede usar para inspeccionar la consulta en sí, por lo que podríamos realizar la consulta de combinación solo en casos con una amenaza predicha para un problema n + 1. Sin embargo, no deberíamos saltar a este nivel de optimización antes de estar seguros de que vale la pena.
Los programadores pierden una enorme cantidad de tiempo pensando o preocupándose por la velocidad de las partes no críticas de sus programas, y estos intentos de eficiencia en realidad tienen un fuerte impacto negativo cuando se consideran la depuración y el mantenimiento. Deberíamos olvidarnos de las pequeñas eficiencias, digamos alrededor del 97% del tiempo: la optimización prematura es la raíz de todos los males.
DataLoader de Facebook ofrece una buena solución para el problema n + 1 entre otros problemas. Más sobre el uso de DataLoader con el servidor Apollo aquí y aquí.
Epílogo
La aplicación que creamos en esta parte no está estructurada de manera óptima: el esquema, las consultas y las mutaciones deben al menos moverse fuera del código de la aplicación. En Internet se pueden encontrar ejemplos para una mejor estructuración de las aplicaciones GraphQL. Por ejemplo, para el servidor aquí y el cliente aquí.
GraphQL ya es una tecnología bastante antigua, que ha sido utilizada por Facebook desde 2012, por lo que ya podemos verla como "probada en batalla". Desde que Facebook publicó GraphQL en 2015, poco a poco ha recibido más y más atención, y en un futuro cercano podría amenazar el dominio de REST. La muerte de REST también ha sido predicha. Aunque eso no sucederá todavía, GraphQL es absolutamente digno de aprender.