a
Estructura de la aplicación backend, introducción a las pruebas
Continuemos nuestro trabajo en el backend de la aplicación de notas que comenzamos en la parte 3.
Estructura del proyecto
Nota: el material de este curso fue escrito con la version v20.11.0. Por favor asegúrate de que tu version de Node es al menos tan nueva como la version utilizada en el material (puedes chequear la version al ejecutar node -v en la linea de comandos).
Antes de pasar al tema de las pruebas, modificaremos la estructura de nuestro proyecto para cumplir con las mejores prácticas de Node.js.
Después de realizar los cambios que explicaremos a continuación, terminaremos con la siguiente estructura:
├── index.js
├── app.js
├── dist
│ └── ...
├── controllers
│ └── notes.js
├── models
│ └── note.js
├── package-lock.json
├── package.json
├── utils
│ ├── config.js
│ ├── logger.js
│ └── middleware.js Hasta ahora hemos estado usando console.log y console.error para imprimir diferente información del código. Sin embargo, esta no es una buena forma de hacer las cosas. Separemos todas las impresiones a la consola en su propio módulo utils/logger.js:
const info = (...params) => {
console.log(...params)
}
const error = (...params) => {
console.error(...params)
}
module.exports = {
info, error
}El logger tiene dos funciones, info para imprimir mensajes de registro normales y error para todos los mensajes de error.
Extraer registros en su propio módulo es una buena idea por varios motivos. Si quisiéramos comenzar a escribir registros en un archivo o enviarlos a un servicio de registro externo como graylog o papertrail solo tendríamos que hacer cambios en un solo lugar.
El manejo de las variables de entorno se extrae a un archivo utils/config.js separado:
require('dotenv').config()
const PORT = process.env.PORT
const MONGODB_URI = process.env.MONGODB_URI
module.exports = {
MONGODB_URI,
PORT
}Las otras partes de la aplicación pueden acceder a las variables de entorno importando el módulo de configuración:
const config = require('./utils/config')
logger.info(`Server running on port ${config.PORT}`)El contenido del archivo index.js utilizado para iniciar la aplicación se simplifica de la siguiente manera:
const app = require('./app') // la aplicación Express real
const config = require('./utils/config')
const logger = require('./utils/logger')
app.listen(config.PORT, () => {
logger.info(`Server running on port ${config.PORT}`)
})El archivo index.js solo importa la aplicación real desde el archivo app.js y luego inicia la aplicación. La función info del módulo de registro se utiliza para la impresión de la consola que indica que la aplicación se está ejecutando.
Ahora, la aplicación Express y el código que se encarga del servidor web están separados siguiendo las mejores prácticas. Una de las ventajas de este método es que ahora la aplicación se puede probar a nivel de llamadas a la API HTTP sin realizar llamadas a través de HTTP por la red, lo que hace que la ejecución de las pruebas sea más rápida.
Los controladores de ruta también se han movido a un módulo dedicado. Los controladores de eventos de las rutas se conocen comúnmente como controladores, y por esta razón hemos creado un nuevo directorio de controllers. Todas las rutas relacionadas con las notas están ahora en el módulo notes.js bajo el directorio controllers.
El contenido del módulo notes.js es el siguiente:
const notesRouter = require('express').Router()
const Note = require('../models/note')
notesRouter.get('/', (request, response) => {
Note.find({}).then(notes => {
response.json(notes)
})
})
notesRouter.get('/:id', (request, response, next) => {
Note.findById(request.params.id)
.then(note => {
if (note) {
response.json(note)
} else {
response.status(404).end()
}
})
.catch(error => next(error))
})
notesRouter.post('/', (request, response, next) => {
const body = request.body
const note = new Note({
content: body.content,
important: body.important || false,
})
note.save()
.then(savedNote => {
response.json(savedNote)
})
.catch(error => next(error))
})
notesRouter.delete('/:id', (request, response, next) => {
Note.findByIdAndDelete(request.params.id)
.then(() => {
response.status(204).end()
})
.catch(error => next(error))
})
notesRouter.put('/:id', (request, response, next) => {
const body = request.body
const note = {
content: body.content,
important: body.important,
}
Note.findByIdAndUpdate(request.params.id, note, { new: true })
.then(updatedNote => {
response.json(updatedNote)
})
.catch(error => next(error))
})
module.exports = notesRouterEsto es casi una copia exacta de nuestro archivo index.js anterior.
Sin embargo, hay algunos cambios importantes. Al principio del archivo, creamos un nuevo objeto router:
const notesRouter = require('express').Router()
//...
module.exports = notesRouterEl módulo exporta el enrutador para que esté disponible para todos los consumidores del módulo.
Todas las rutas están ahora definidas para el objeto enrutador, de manera similar a lo que habíamos hecho anteriormente con el objeto que representa la aplicación completa.
Vale la pena señalar que las rutas en los controladores de ruta se han acortado. En la versión anterior teníamos:
app.delete('/api/notes/:id', (request, response, next) => {Y en la versión actual, tenemos:
notesRouter.delete('/:id', (request, response, next) => {Entonces, ¿qué son exactamente estos objetos de enrutador? El manual de Express proporciona la siguiente explicación:
Un objeto de enrutador es un instancia aislada de middleware y rutas. Puedes pensar en ella como una "mini-aplicación", capaz solo de realizar funciones de middleware y enrutamiento. Cada aplicación Express tiene un enrutador de aplicación incorporado.
El enrutador es de hecho un middleware, que se puede utilizar para definir "rutas relacionadas" en un solo lugar, que normalmente se coloca en su propio módulo.
El archivo app.js que crea la aplicación real , toma el enrutador como se muestra a continuación:
const notesRouter = require('./controllers/notes')
app.use('/api/notes', notesRouter)El enrutador que definimos anteriormente se usa si la URL de la solicitud comienza con /api/notes. Por esta razón, el objeto notesRouter solo debe definir las partes relativas de las rutas, es decir, la ruta vacía / o solo el parámetro /:id.
Después de realizar estos cambios, nuestro archivo app.js se ve así:
const config = require('./utils/config')
const express = require('express')
const app = express()
const cors = require('cors')
const notesRouter = require('./controllers/notes')
const middleware = require('./utils/middleware')
const logger = require('./utils/logger')
const mongoose = require('mongoose')
mongoose.set('strictQuery', false)
logger.info('connecting to', config.MONGODB_URI)
mongoose.connect(config.MONGODB_URI)
.then(() => {
logger.info('connected to MongoDB')
})
.catch((error) => {
logger.error('error connecting to MongoDB:', error.message)
})
app.use(cors())
app.use(express.static('dist'))
app.use(express.json())
app.use(middleware.requestLogger)
app.use('/api/notes', notesRouter)
app.use(middleware.unknownEndpoint)
app.use(middleware.errorHandler)
module.exports = appEl archivo utiliza un middleware diferente, y uno de ellos es el notesRouter que se adjunta a la ruta /api/notes.
Nuestro middleware personalizado se ha movido a un nuevo módulo utils/middleware.js:
const logger = require('./logger')
const requestLogger = (request, response, next) => {
logger.info('Method:', request.method)
logger.info('Path: ', request.path)
logger.info('Body: ', request.body)
logger.info('---')
next()
}
const unknownEndpoint = (request, response) => {
response.status(404).send({ error: 'unknown endpoint' })
}
const errorHandler = (error, request, response, next) => {
logger.error(error.message)
if (error.name === 'CastError') {
return response.status(400).send({ error: 'malformatted id' })
} else if (error.name === 'ValidationError') {
return response.status(400).json({ error: error.message })
}
next(error)
}
module.exports = {
requestLogger,
unknownEndpoint,
errorHandler
}La responsabilidad de establecer la conexión con la base de datos se ha entregado al módulo app.js. El archivo note.js del directorio models solo define el esquema de Mongoose para las notas.
const mongoose = require('mongoose')
const noteSchema = new mongoose.Schema({
content: {
type: String,
required: true,
minlength: 5
},
important: Boolean,
})
noteSchema.set('toJSON', {
transform: (document, returnedObject) => {
returnedObject.id = returnedObject._id.toString()
delete returnedObject._id
delete returnedObject.__v
}
})
module.exports = mongoose.model('Note', noteSchema)Para recapitular, la estructura del directorio se ve así después de que se hayan realizado los cambios:
├── index.js
├── app.js
├── dist
│ └── ...
├── controllers
│ └── notes.js
├── models
│ └── note.js
├── package-lock.json
├── package.json
├── utils
│ ├── config.js
│ ├── logger.js
│ └── middleware.js Para aplicaciones más pequeñas, la estructura no importa mucho. Una vez que la aplicación comienza a crecer en tamaño, tendrá que establecer algún tipo de estructura y separar las diferentes responsabilidades de la aplicación en módulos separados. Esto facilitará mucho el desarrollo de la aplicación.
No existe una estructura de directorio estricta o una convención de nomenclatura de archivos que se requiera para las aplicaciones Express. Para contrastar esto, Ruby on Rails requiere una estructura específica. Nuestra estructura actual simplemente sigue algunas de las mejores prácticas que puedes encontrar en Internet.
Puedes encontrar el código para nuestra aplicación actual en su totalidad en la rama part4-1 de este repositorio de GitHub.
Si clonas el proyecto para ti mismo, ejecuta el comando npm install antes de iniciar la aplicación con npm run dev.
Nota sobre las exportaciones
Hemos utilizado dos tipos diferentes de exportaciones en esta parte. En primer lugar, por ejemplo, el archivo utils/logger.js realiza la exportación de la siguiente manera:
const info = (...params) => {
console.log(...params)
}
const error = (...params) => {
console.error(...params)
}
module.exports = { info, error}El archivo exporta un objeto que tiene dos campos, ambos son funciones. Las funciones pueden ser utilizadas de dos maneras diferentes. La primera opción es requerir todo el objeto y hacer referencia a las funciones a través del objeto utilizando la notación de punto:
const logger = require('./utils/logger')
logger.info('message')
logger.error('error message')La otra opción es desestructurar las funciones en sus propias variables en la declaración de require:
const { info, error } = require('./utils/logger')
info('message')
error('error message')La segunda forma de exportar puede ser preferible si solo se utiliza una pequeña parte de las funciones exportadas en un archivo. Por ejemplo, en el archivo controller/notes.js, la exportación se realiza de la siguiente manera:
const notesRouter = require('express').Router()
const Note = require('../models/note')
// ...
module.exports = notesRouterEn este caso, solo se exporta una "cosa", por lo que la única forma de usarla es la siguiente:
const notesRouter = require('./controllers/notes')
// ...
app.use('/api/notes', notesRouter)Ahora, la "cosa" exportada (en este caso, un objeto de router) se asigna a una variable y se utiliza como tal.
Encontrar los usos de tus exportaciones con VS Code
VS Code tiene una característica útil que te permite ver dónde se han exportado tus módulos. Esto puede ser muy útil para refactorizar. Por ejemplo, si decides dividir una función en dos funciones separadas, tu código podría romperse si no modificas todos los usos. Esto es difícil si no sabes dónde están. Sin embargo, necesitas definir tus exportaciones de una manera particular para que esto funcione.
Si haces clic derecho en una variable en el lugar donde se exporta y seleccionas "Buscar todas las referencias", te mostrará todos los lugares donde se importa la variable. Sin embargo, si asignas un objeto directamente a module.exports, no funcionará. Una solución es asignar el objeto que deseas exportar a una variable con nombre y luego exportar la variable con nombre. Tampoco funcionará si haces una desestructuración al importar; debes importar la variable con nombre y luego desestructurar, o simplemente utilizar la notación de punto para usar las funciones contenidas en la variable con nombre.
Esta característica de VS Code afectando la forma en que escribes tu código probablemente no sea ideal, así que debes decidir por ti mismo si seguir estas reglas vale la pena.
Testing de aplicaciones Node
Hemos descuidado por completo un área esencial del desarrollo de software, y es la prueba automatizada.
Comencemos nuestro viaje de prueba mirando las pruebas unitarias. La lógica de nuestra aplicación es tan simple, que no hay mucho que tenga sentido probar con pruebas unitarias. Creemos un nuevo archivo utils/for_testing.js y escribamos un par de funciones simples que podamos usar para practicar escribir pruebas:
const reverse = (string) => {
return string
.split('')
.reverse()
.join('')
}
const average = (array) => {
const reducer = (sum, item) => {
return sum + item
}
return array.reduce(reducer, 0) / array.length
}
module.exports = {
reverse,
average,
}La función average usa el método de array reduce. Si el método aún no te resulta familiar, ahora es un buen momento para ver los primeros tres videos de la serie Functional Javascript en Youtube.
Hay un gran número de librerías de pruebas, o test runners, disponibles para JavaScript. El antiguo rey de las librerías de pruebas es Mocha, que fue reemplazado hace unos años por Jest. Un recién llegado a las librerías es Vitest, que se presenta como una nueva generación de librerías de pruebas.
Hoy en día, Node también tiene una librería de pruebas integrada node:test, que se adapta bien a las necesidades del curso.
Definamos el script npm test para ejecutar pruebas:
{
//...
"scripts": {
"start": "node index.js",
"dev": "nodemon index.js",
"build:ui": "rm -rf build && cd ../frontend/ && npm run build && cp -r build ../backend",
"deploy": "fly deploy",
"deploy:full": "npm run build:ui && npm run deploy",
"logs:prod": "fly logs",
"lint": "eslint .",
"test": "node --test" },
//...
}Creemos un directorio separado para nuestras pruebas llamado tests y creemos un nuevo archivo llamado reverse.test.js con el siguiente contenido:
const { test } = require('node:test')
const assert = require('node:assert')
const reverse = require('../utils/for_testing').reverse
test('reverse of a', () => {
const result = reverse('a')
assert.strictEqual(result, 'a')
})
test('reverse of react', () => {
const result = reverse('react')
assert.strictEqual(result, 'tcaer')
})
test('reverse of saippuakauppias', () => {
const result = reverse('saippuakauppias')
assert.strictEqual(result, 'saippuakauppias')
})En la primera linea, el archivo de prueba importa la función a ser probada y la asigna a una variable llamada reverse:
La prueba define la palabra clave test y la librería assert, que es utilizada por las pruebas para verificar los resultados de las funciones bajo prueba.
En la siguiente fila, el archivo de prueba importa la función a ser probada y la asigna a una variable llamada reverse:
const reverse = require('../utils/for_testing').reverseLos casos de prueba individual se definen con la función test. El primer argumento de la función es la descripción de la prueba como una cadena. El segundo argumento es una función, que define la funcionalidad para el caso de prueba. La funcionalidad para el segundo caso de prueba se ve así:
() => {
const result = reverse('react')
assert.strictEqual(result, 'tcaer')
}Primero, ejecutamos el código que se va a probar, es decir, generamos un reverso para el string react. Luego, verificamos los resultados con el método strictEqual de la librería assert.
Como se esperaba, todas las pruebas pasan:
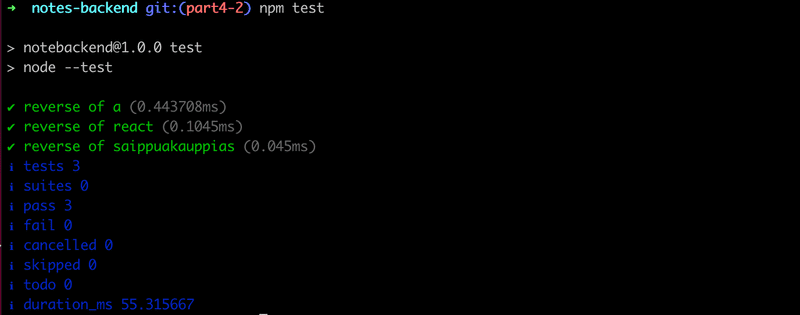
La librería node:test espera por defecto que los nombres de los archivos de prueba contengan .test. En este curso, seguiremos la convención de nombrar nuestros archivos de prueba con la extensión .test.js.
Vamos a romper el test:
test('reverse of react', () => {
const result = reverse('react')
assert.strictEqual(result, 'tkaer')
})Ejecutar esta prueba da como resultado el siguiente mensaje de error:

Pongamos las pruebas para la función average, en un nuevo archivo llamado tests/average.test.js.
const { test, describe } = require('node:test')
// ...
const average = require('../utils/for_testing').average
describe('average', () => {
test('of one value is the value itself', () => {
assert.strictEqual(average([1]), 1)
})
test('of many is calculated right', () => {
assert.strictEqual(average([1, 2, 3, 4, 5, 6]), 3.5)
})
test('of empty array is zero', () => {
assert.strictEqual(average([]), 0)
})
})La prueba revela que la función no funciona correctamente con un array vacío (esto se debe a que en JavaScript dividir por cero da como resultado NaN)
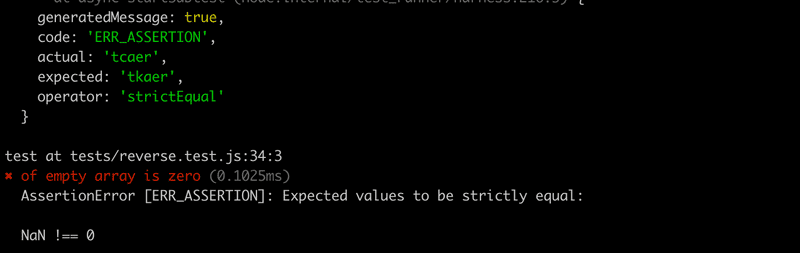
Arreglar la función es bastante fácil:
const average = array => {
const reducer = (sum, item) => {
return sum + item
}
return array.length === 0
? 0
: array.reduce(reducer, 0) / array.length
}Si la longitud del array es 0, devolvemos 0, y en todos los demás casos usamos el método reduce para calcular el promedio.
Hay algunas cosas a tener en cuenta sobre las pruebas que acabamos de escribir. Definimos un bloque describe alrededor de las pruebas al que se le dio el nombre average:
describe('average', () => {
// tests
})Se pueden usar bloques de descripción para agrupar pruebas en colecciones lógicas. La salida de prueba también usa el nombre del bloque describe:
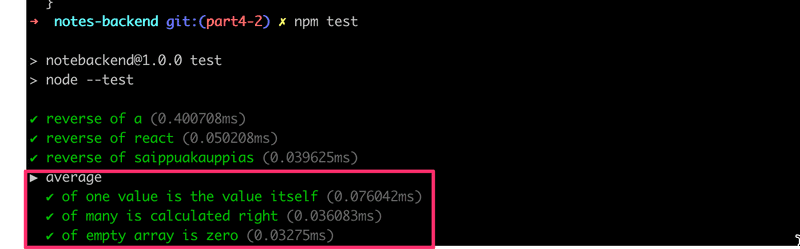
Como veremos más adelante, los bloques describe son necesarios cuando queremos ejecutar algunas operaciones de instalación o desmontaje compartidas para un grupo de pruebas.
Otra cosa a tener en cuenta es que escribimos las pruebas de una manera bastante compacta, sin asignar la salida de la función que se está probando a una variable:
test('of empty array is zero', () => {
assert.strictEqual(average([]), 0)
})Ejercicios 4.3.-4.7.
Creemos una colección de funciones auxiliares que estén destinadas a trabajar con las secciones describe de la lista de blogs. Crea las funciones en un archivo llamado utils/list_helper.js. Escribe tus pruebas en un archivo de prueba con el nombre apropiado en el directorio tests.
4.3: Funciones Auxiliares y Pruebas Unitarias, paso 1
Primero define una función dummy que reciba un array de publicaciones de blog como parámetro y siempre devuelva el valor 1. El contenido del archivo list_helper.js en este punto debe ser el siguiente:
const dummy = (blogs) => {
// ...
}
module.exports = {
dummy
}Verifica que tu configuración de prueba funcione con la siguiente prueba:
const { test, describe } = require('node:test')
const assert = require('node:assert')
const listHelper = require('../utils/list_helper')
test('dummy returns one', () => {
const blogs = []
const result = listHelper.dummy(blogs)
assert.strictEqual(result, 1)
})4.4: Funciones Auxiliares y Pruebas Unitarias, paso 2
Define una nueva función totalLikes que recibe una lista de publicaciones de blogs como parámetro. La función devuelve la suma total de likes en todas las publicaciones del blog.
Escribe pruebas apropiadas para la función. Se recomienda poner las pruebas dentro de un bloque describe, para que la salida del informe de prueba se agrupe bien:

Definir datos de prueba para la función se puede hacer así:
describe('total likes', () => {
const listWithOneBlog = [
{
_id: '5a422aa71b54a676234d17f8',
title: 'Go To Statement Considered Harmful',
author: 'Edsger W. Dijkstra',
url: 'https://homepages.cwi.nl/~storm/teaching/reader/Dijkstra68.pdf',
likes: 5,
__v: 0
}
]
test('when list has only one blog, equals the likes of that', () => {
const result = listHelper.totalLikes(listWithOneBlog)
assert.strictEqual(result, 5)
})
})Si definir tu propia lista de datos de prueba de blogs es demasiado trabajo, puedes usar la lista ya hecha aquí.
Es probable que tengas problemas al escribir pruebas. Recuerda las cosas que aprendimos sobre depuración en la parte 3. Puedes imprimir cosas en la consola con console.log incluso durante la ejecución de la prueba.
4.5*: Funciones Auxiliares y Pruebas Unitarias, paso 3
Define una nueva función favoriteBlog que recibe una lista de blogs como parámetro. La función descubre qué blog tiene más me gusta. Si hay muchos favoritos, basta con devolver uno de ellos.
El valor devuelto por la función podría tener el siguiente formato:
{
title: "Canonical string reduction",
author: "Edsger W. Dijkstra",
likes: 12
}NB cuando estás comparando objetos, el método deepStrictEqual es probablemente lo que debas usar, strictEqual intenta verificar que los dos valores sean el mismo valor, y no solo que contengan las mismas propiedades. Para conocer las diferencias entre las distintas funciones del módulo assert, puedes consultar esta respuesta Stack Overflow.
Escribe las pruebas para este ejercicio dentro de un nuevo bloque describe. Haz lo mismo con los ejercicios restantes también.
4.6*: Funciones Auxiliares y Pruebas Unitarias, paso 4
Este y el siguiente ejercicio son un poco más desafiantes. No es necesario completar estos dos ejercicios para avanzar en el material del curso, por lo que puede ser una buena idea volver a estos una vez que haya terminado de leer el material de esta parte en su totalidad.
Se puede terminar este ejercicio sin el uso de librerías adicionales. Sin embargo, este ejercicio es una gran oportunidad para aprender a usar la librería Lodash.
Define una función llamada mostBlogs que reciba una lista de blogs como parámetro. La función devuelve el author que tiene la mayor cantidad de blogs. El valor de retorno también contiene el número de blogs que tiene el autor principal:
{
author: "Robert C. Martin",
blogs: 3
}Si hay muchos blogueros importantes, entonces es suficiente con devolver uno de ellos.
4.7*: Funciones Auxiliares y Pruebas Unitarias, paso 5
Define una función llamada mostLikes que reciba una lista de blogs como parámetro. La función devuelve el autor, cuyas publicaciones de blog tienen la mayor cantidad de me gusta. El valor de retorno también contiene el número total de likes que el autor ha recibido:
{
author: "Edsger W. Dijkstra",
likes: 17
}Si hay muchos bloggers importantes, entonces es suficiente para mostrar cualquiera de ellos.